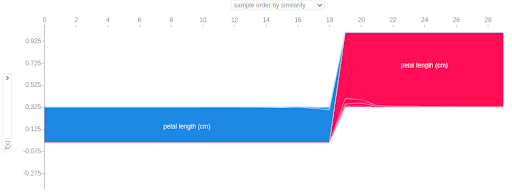
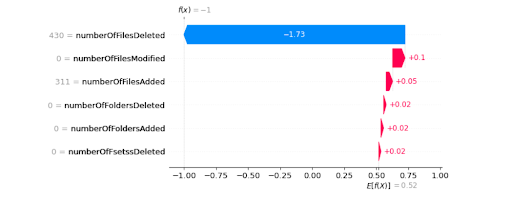
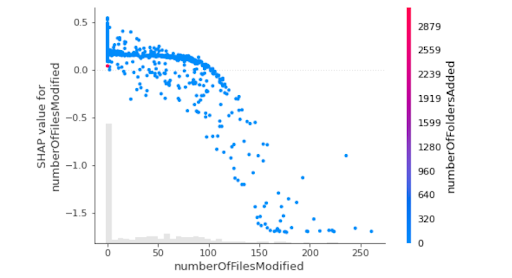
Fig:2(b). Observation Explanation.
Data Resiliency — An Unsupervised Anomaly Detection Initiative from Druva Labs
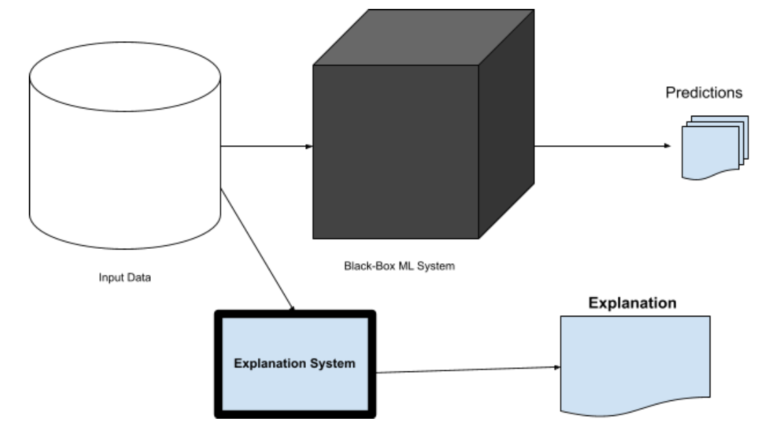
As we covered previously, using SHAP for model explanation can offer helpful insights into model behaviors globally (for the entire dataset) as well as locally (per observation). For the supervised ML algorithms SHAP support is sufficient, things get tricky when we come to unsupervised machine learning techniques.
One of our Machine learning initiatives is an anomaly detection system for data resilience, which is a log-based, dynamic outlier detection method. We evaluated many algorithms for this purpose including distance-based, density-based, and clustering algorithms, and one of the top contenders is the tree-based isolation forest. Although achieving good model accuracy with low false-positive predictions is the primary goal, providing explainability in terms of feature contributions for each prediction to the end-users was also a major requirement.
In the following section, we’ll explore how we addressed this requirement with some example visualizations.
Model Explainability using SHAP for Isolation Forest
During our evaluation, we understood how isolation forest can be utilized for multidimensional anomaly detection. We tested it alongside many other anomaly detection algorithms, but due to its simple structure and low runtime complexity, isolation forest was a popular choice. For providing model explainability, we utilized the SHAP python library. The following sections will walk through the isolation algorithm and demonstrate how we used SHAP for explainability.
Anomaly Detection with Isolation Forest
Isolation forest is a popular unsupervised anomaly detection algorithm. It detects anomalies using isolation rather than trying to model normal points. Isolation forests are built using decision trees.
The basic workflow for isolation forest-based anomaly detection is as follows:
- Randomly select a feature from the given set of features.
- Randomly select a split value for the feature between the minimum and maximum value.
- The data is partitioned on the split value of that feature.
- Continuous recursive partitioning is done until an instance is isolated.
- The path length from root to terminating node is equivalent to the number of splittings, and an anomalous instance will have a shorter path length or fewer splittings for isolation.
- The path length averaged over a forest of many such isolation trees is a measure of the normality of data and our decision function.
SHAP for Isolation Forest
The explainability of an anomaly detection algorithm like isolation forest answers the following questions:
- Why is a particular observation considered anomalous by the model?
- Which features contributed to identifying an observation as an anomaly and which didn’t?
- How can the output of the model on a real-world dataset be interpreted?
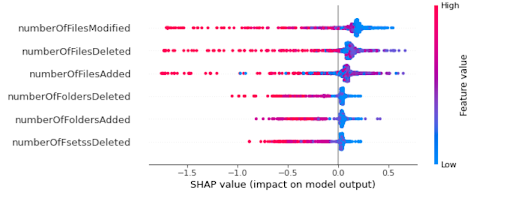
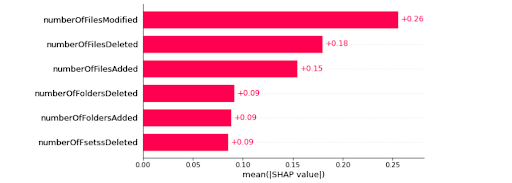
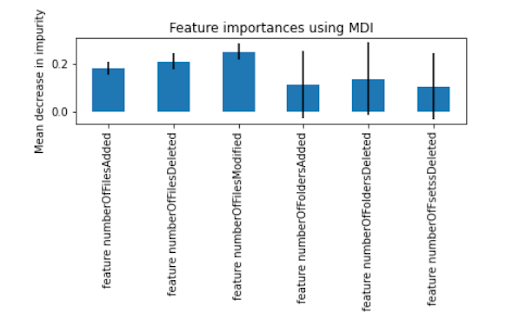
The interpretation can be either global or local. In global, we need to explain the model as a whole and understand which features play a more relevant role in the model. Whereas local interpretations look at individual observations and explain the feature contributions that resulted in the given prediction for that observation.
For the purpose of this blog, let’s consider a sample of the dataset we created for the proof of concept phase of our unsupervised anomaly detection for unusual activity detection use case.
In this sample dataset, there are 1,000 observations and many features, but for simplicity, here we selected only six top features. The features represent user activity detected during a backup, such as count of files added, count of files deleted, count of files modified, count of folders added, count of folders deleted, and count of files renamed. Our objective was to use these features as representatives of user activity and detect any unusual user behavior that could have been caused by human error, malicious intent, or a malware/ransomware attack on the system.
For unsupervised anomaly detection, we fit an isolation forest model using the implementation by Sklearn library. The labels generated by the models are stored in a new column, where -1 represents an anomalous, and 1 represents a normal observation. We then used SHAP to explain the predictions for both local and global interpretability.
Explain Single Predictions
Once a prediction is made by the trained unsupervised anomaly detection model we can compute SHAP values. We used TreeExplainer and Explainer objects for our isolation forest model. Below are some of the analyses we could perform using SHAP.