Protecting cloud-native workloads is crucial for maintaining data security and ensuring business continuity in dynamic cloud environments. However, Fair Usage Policies enforced by cloud providers can put performance limitations in backup and recovery processes. In this blog, we will explore these limitations and provide strategies for mitigating their impact.
Tech/Engineering
Throttles: The Hidden Challenge in Protecting Cloud-Native Workloads

When Throttling Halts Cloud Data Recovery
Imagine you are in the middle of a critical data recovery… and suddenly the process slows down. This is often due to API throttling. Cloud providers limit the number of requests your system can make in a given period as a fair usage policy is implemented in multi-tenant systems. While these limits protect cloud infrastructure, they can disrupt data protection operations when speed is critical.
As organizations increasingly migrate to the cloud for enhanced scalability, flexibility and cost efficiency, cloud-native workloads have become the go-to solution for deploying modern applications. Protecting these cloud-native workloads is essential to maintain data security and ensure business continuity in ever-evolving cloud environments. While the cloud offers significant advantages, it also brings new challenges - one of the most overlooked being Service Quotas / Throttles.
API Limits: Hidden Rules Governing Your Cloud Operations
Cloud providers use throttling mechanisms to ensure fair resource distribution, prevent overuse, and maintain service stability in multi-tenant distributed environments. These limits can apply to factors like requests per second, data transfer volume, network usage, vCPU quotas, and more. Throttling can occur at various levels, including service, region, account or subscription.
When throttling kicks in, users may face delays or temporary restrictions until their resource usage falls within acceptable limits.
Here are some examples.
Service | Level | Limits |
AWS S3 | S3 Prefix |
|
AWS EBS | Snapshot |
|
AWS EBS | Account |
|
AWS EBS | Account |
|
Azure Standard storage | Storage Account |
|
Azure vCPUs | Subscription |
|
This is not an exhaustive list. More details for Azure services can be found here. For AWS, documentation of each service mentions quotas/API limits, examples including DDB and S3.
Some limits are hard limits, while few quotas can be increased by submitting a service request to the cloud provider.
What This Means for Your Backup and Restore Experience
Druva’s data protection solution is integrated with cloud providers’ APIs to get access to application data. Each cloud-native workload requires a distinct method of data access for backup and restore workflows. For example, EC2 uses EBS direct APIs. S3 uses S3 APIs. Azure SQL uses Bulk Copy Program (BCP).
Cloud-native workloads typically involve very large data volumes, and to meet RTO and RPO requirements, backup and restores must be extremely fast. While Druva products are capable of achieving these rates, cloud limitations may prevent customers from reaching the maximum potential.
Data protection workflows often compete with other applications on these quotas.
Let’s take an example of EC2 workload in two hypothetical scenarios. Druva’s products use the below APIs during EC2 protection.
Workflow | EBS Direct API |
EC2 Backup |
|
EC2 Restore |
|
A typical deployment includes a high performance agent within Druva’s account, which drives the data transfer and securely stores data in Druva’s cloud. Below diagram illustrates the restore workflow.
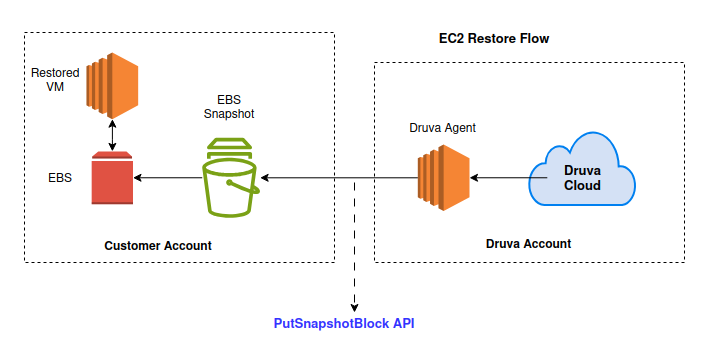
Scenario 1:
Consider a scenario where one large EC2 VM with a single disk of 10TB needs to be restored.
This workflow uses EBS direct API - PutSnapshotBlock. It has a hard limit of 1000 APIs per sec for each EBS snapshot. EBS uses a block size of 512KB. This translates to a data processing limit of 1.7TB per hour. Hence, restore time for this EC2 will always be greater than 6Hrs.
Scenario 2:
A customer has hundreds of VMs in a single account, aggregating to 200TB of EBS size. This account needs to be restored.
Multiple VMs can be restored parallel to speed-up the process. This workflow uses EBS direct API - PutSnapshotBlock. It has a default limit of 5000 APIs per sec for one account (in the US-east-1 region). Considering the EBS block size of 512KB, this translates to a data processing rate of 8.6TB per hour. This means the process of restoring the whole account will take more than 24 hours.
If the RTO is more stringent, then the account level service quota must be increased to process more than 5000 APIs per sec.
How to Mitigate Impact Throttles
While it's impossible to completely eliminate the impact of API throttling, its effects can be significantly reduced through thoughtful planning and proactive strategies.
Perform a thorough sizing exercise to determine resource requirements and tune service quota whenever possible for high priority workloads.
Proper scheduling of backup jobs is required, so that backup can get enough resources to complete faster, and other applications are not impacted.
Automated Monitoring and Alerts can be used to track API usage, and backup and restore strategies can be adjusted.
For many jobs, scheduling can stagger jobs over time, to avoid peaks in API usage.
How Druva agent handles throttles:
Efficient change detection algorithms to keep IO operations in limits.
Rate limiters within the data pipeline ensure flow is kept within limits, minimizing throttle errors and retries. Efficient backoff and retry logic is implemented to handle throttle errors.
VM instances come with their own limits. Many times they provide burst capacity. That means after the credits are exhausted, the instance scales down to baseline capacity. Proper instance sizing for Druva compute is required to ensure optimal performance and efficient resource utilization.
Druva's products are future-ready - when cloud providers increase service quotas, Druva’s data pipeline can seamlessly leverage these improvements without significant design changes.
Conclusion
Service Quotas and Throttles in cloud environments are often an overlooked risk, but it can significantly disrupt cloud-native backup and recovery processes. By understanding the impact of API limits and taking proactive steps to mitigate them, businesses can safeguard their data more effectively and ensure that their cloud-native workloads remain resilient.
Learn more about Druva’s cloud-native solutions for protecting public cloud data here.