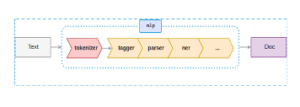
While processing, Spacy first tokenizes the raw text, assigns POS tags, identifies the relation between tokens like subject or object, labels named ‘real-world’ objects like persons, organizations, or locations, and finally returns the processed text with linguistic annotations with entities from the text. Spacy does not use the output of tagger and parser for NER, so you can skip these pipelines while processing, as shown below.
import spacy
data = "Druva a data protection company headquartered in California was founded by Jaspreet Singh and Milind Borate."
nlp = spacy.load('en_core_web_sm', pipeline=["ner"])
for ent in nlp(data).ents:
print(ent.text, ent.label_)
|
Druva GPE
California GPE
Jaspreet Singh PERSON
Milind Borate ORG
|
Stanford Core NLP (Stanza)
The Stanford NER classifier is also called the Conditional Random Field (CRF) classifier. This provides a general implementation of a linear chain CRF model.
NER processing pipeline:
- Tokenizer splits the raw text into sentences and words.
- The Multi-Word Token (MWT) expansion module expands the token into multiple syntactic words. This pipeline is specific to languages with multi-word token, like French or German. Languages such as English do not support it.
- NER classifier receives the annotated data and assigns labels to an entity, like PERSON, ORGANIZATION, LOCATION.
import stanza
stanza.download("en")
data = "Druva a data protection company headquartered in California was founded by Jaspreet Singh and Milind Borate."
nlp = stanza.Pipeline(lang='en', processors='tokenize,ner')
doc = nlp(data)
for sent in doc.sentences:
for ent in sent.ents:
print(ent.tex,t ent.type)
|
Druva ORG
California GPE
Jaspreet Singh PERSON
Milind Borate PERSON
|
Polyglot
Polyglot NER does not use human-annotated training datasets. Rather, it uses huge unlabeled datasets (like Wikipedia) with automatically inferred entities using the hyperlinks.
The following example shows how to identify entities by cross-linking with Wikipedia.
<ENTITY url="https://en.wikipedia.org/wiki/Michael_I._Jordan"> Michael Jordan </ENTITY> is a professor at <ENTITY url="https://en.wikipedia.org/wiki/University_of_California,_Berkeley"> Berkeley </ENTITY>
Polyglot's object-oriented implementation simplifies its use for NLP features.
Applying the model on raw text, Polyglot provides a processed text with data including sentences, words, entities, and POS tags.
from polyglot.text import Text
data = "Druva, a data protection company headquartered in California was founded by Jaspreet Singh and Milind Borate."
text = Text(data, hint_language_code='en')
for each in text.entities:
print(' '.join(each), each.tag)
|
California I-LOC
Jaspreet Singh I-PER
Milind Borate I-PER
|
Comparison
1. Performance
For experiments, the input text file used was 250KB, and the test machine was used with configurations of 2 Cores and a 4GB Memory.
| | NLTK | Spacy | Stanza | Polyglot |
| Time (sec) | 14 | 3.15 | 184 | 7.6 |
| CPU | 1 core 100% | 1 core 100% | 2 core 100% | 1 core 100% |
| Memory | 340 MB | 1.1 GB | 1.6 GB | 150 MB |
2. Comparison
The table below provides guidelines on when to consider using specific models.
| | NLTK | Spacy | Stanza | Polyglot |
| Beginner | yes | yes | yes | yes |
| Multi-language support | yes | yes | yes | yes |
| Entity categories | 7 | 18 | 3/4/7 | 3 |
| CPU efficient application | yes | yes | no | yes |
| Model | Supervised | Supervised | Supervised | Semi-Supervised |
| Programming Language | Python | Python | Python/Java | Python |
3. Accuracy:
There are accuracy variations of NER results for given examples as pre-trained models of libraries used for experiments.
Conclusion
These observations are for NLTK, Spacy, CoreNLP (Stanza), and Polyglot using pre-trained models provided by open-source libraries. There are many other open-source libraries which can be used for NLP.
NLTK is one of the oldest, and most widely adopted methods for research and educational purposes. Spacy is object-oriented with customizable options, works fast, and is considered the current industry-standard. Stanford CoreNLP is slow for NLP production usage, but can integrate with NLTK to boost CPU efficiency. Polyglot is a lesser-known library, but is efficient, straightforward, and works fast. Using Polyglot is similar to using Spacy and a good choice for projects involving language which Spacy does not support. Unlike other libraries, Polyglot works better at processing unusual or informal text/speech where natural language rules are not followed.
Explore the many ways Druva’s innovative solutions are enabling a range of next-generation cloud-based applications, such as those for neural networks, in the Tech/Engineering section of the blog archive.