Neural networks are exciting new trends in technology because they provide practical forms of machine intelligence that can solve many use cases within different technology domains — from data search optimization to data storage optimization. However, when we start to dive deeper to understand the concepts of neural networks, many developers find themselves overwhelmed by the associated mathematical models and formulas. To solve this problem, I will introduce you to a practical approach to easily understand what a neural network is in machine learning through visualization using TensorFlow Playground.
What is TensorFlow Playground?
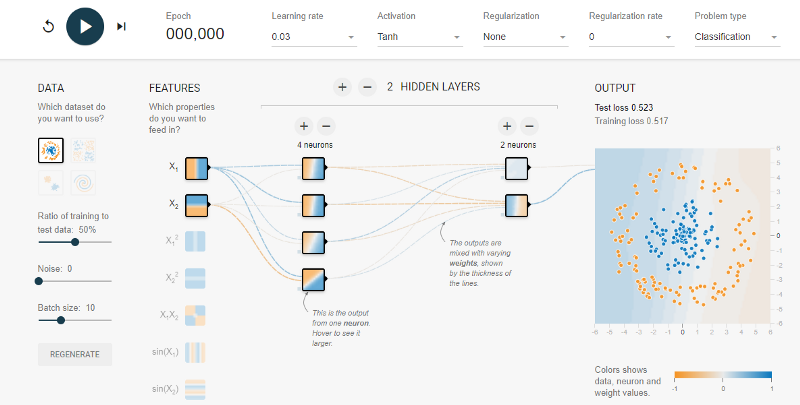
Google developed an open-source application that is well known for explaining how neural networks work in an interactive way: TensorFlow Playground. TensorFlow Playground is a web application that is written in d3.js (JavaScript), and it allows users to test the artificial intelligence (AI) algorithm with the TensorFlow machine learning library.