Data silos are isolated data repositories. These are common in organizations that store and manage data independently. When silos are not managed properly, they can become a liability instead of an asset. Building a data pipeline is an effective way to manage data silos.
This article explores the design of a data pipeline that feeds a warehouse with data from multiple heterogeneous stores within a SaaS product ecosystem. We will also go through the results and benefits of implementing this design.
Problems with Data Silos
In the dynamic landscape of SaaS cloud platforms based on microservices architecture, data silos are an all-too-common challenge.
In a microservices setup, each microservice maintains its data store leading to fragmented data and difficulties in achieving a unified view of the organization's information. Accessing data across multiple microservices can result in slow retrieval and increased latency. Implementing uniform security and access control can be complex, and addressing data ownership and accountability issues are additional hurdles.
A robust data pipeline is not just a necessity but a strategic asset in such an environment. This pipeline must be adaptable to a multitude of use cases, ranging from data analytics and dashboarding to reporting and machine learning. To meet these diverse demands, data must be collected from various subsystems and centralized in a warehouse or data lake.
Key Considerations for the Pipeline Design
To ensure the data pipeline can handle these diverse use cases effectively, several key considerations should guide its design.
Scalability and elasticity
Scalability to seamlessly handle growing data volumes, microservices, and user demands.
Autoscaling mechanisms to adapt to changing workloads.
Performance
Ability to handle full data or just incremental data from diverse sources to meet Service Level Agreements (SLAs).
Flexibility
Flexibility to integrate different data sources and the ability to adapt to changing business requirements.
Ability to fetch data from multiple data sources but store it in the same table in the warehouse.
Fault tolerance
Error handling and retry mechanisms to gracefully handle transient failures.
DevOps and CI/CD Integration
Automated configuration management and infrastructure provisioning to streamline pipeline maintenance.
Data Pipeline Solution
A data pipeline can take various forms, such as batch processing or stream processing. For the use cases we've mentioned, a batch processing pipeline is suitable where a high volume of data is moved at regular intervals. Several options are available that include AWS-native solutions like AWS Data Migration Service, AWS Data Pipeline Service, AWS Glue, and Apache Airflow, as well as third-party solutions like Hevo.
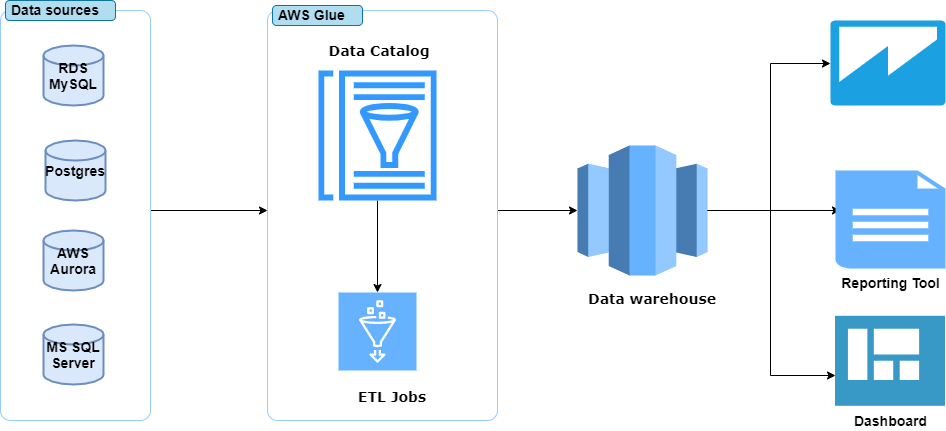
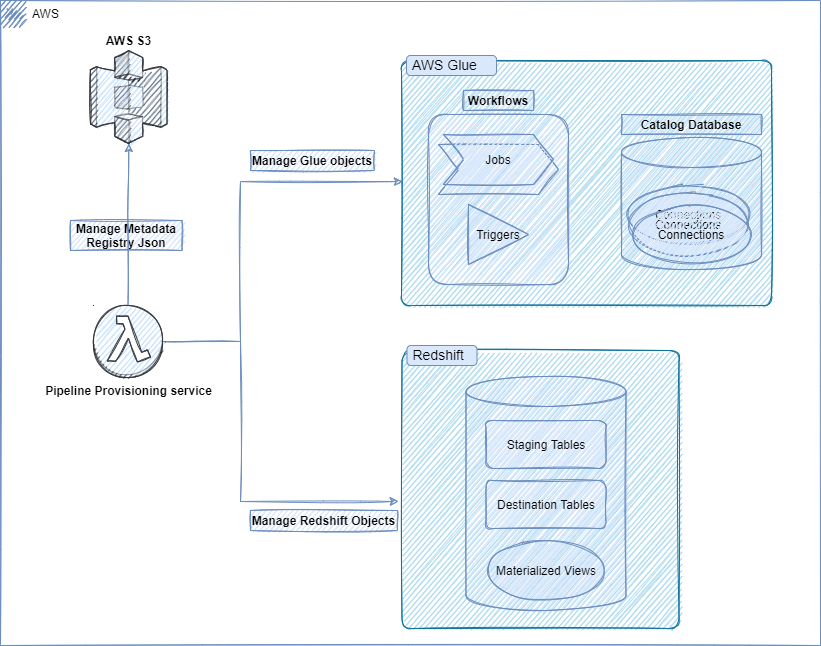
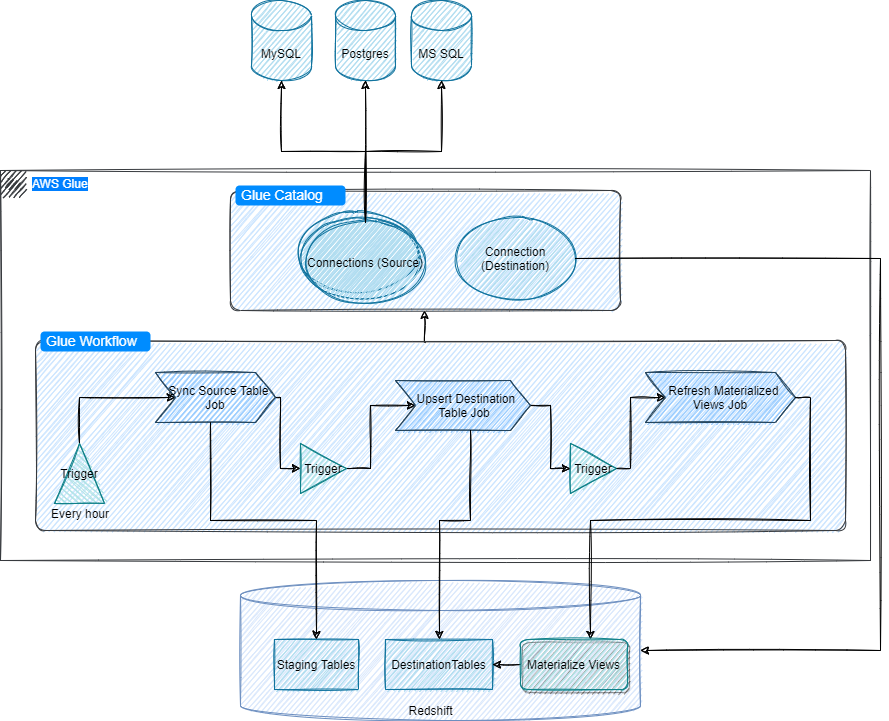
Data Pipeline Based on AWS Glue and Redshift
If the product tech stack is based on the AWS platform, then AWS Glue stands out as the preferred choice for data processing. It is a fully managed serverless platform that provides elastic scalability and offers cost optimization through a pay-as-you-go model. It is also optimized to work seamlessly with cloud-based data sources and destinations.
Redshift, a go-to store for warehouse solutioning in AWS, is a petabyte-scale data warehouse that can handle both structured and semi-structured data. It has materialized views that can be leveraged to create a flat list of raw data by joining multiple tables present at the central place based on some business logic. This is very useful for our use cases as views can provide fast retrieval of enriched data for downstream processing.