
What is a disaster recovery plan (DRP) and why do we need one?
A disaster recovery plan is a documented set of procedures and policies that describe how an organization will restore IT systems, data, and operations after a disruptive event (natural disaster, cyberattack, hardware failure, human error). You need one to minimize downtime, reduce financial and reputational losses, meet legal or regulatory requirements, and ensure critical services return quickly and predictably.
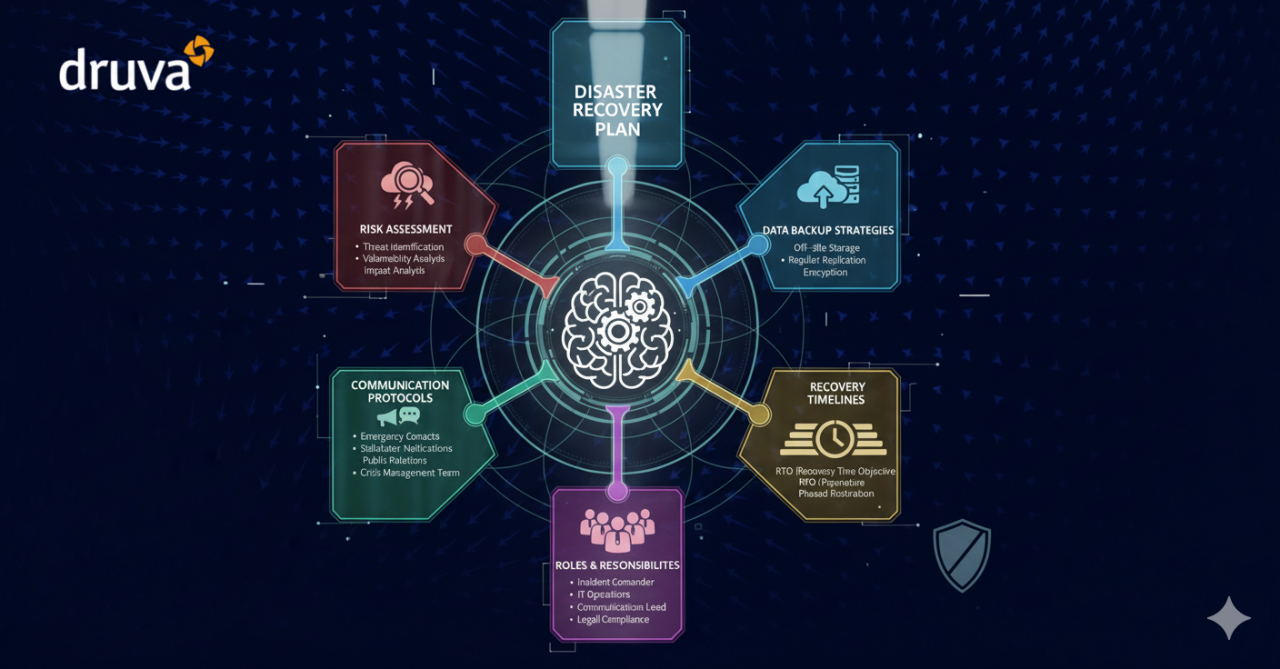
What are the critical components of an effective disaster recovery plan?
- Business impact analysis (BIA) to identify critical systems and acceptable downtime
- Recovery Time Objective (RTO) and Recovery Point Objective (RPO) for each system/data set
- Inventory of hardware, software, data, and key personnel with roles and contact information
- Recovery procedures (step-by-step) and fallback options (e.g., alternate sites, cloud failover)
- Backup strategy and verification processes
- Communication plan (internal and external) and escalation matrix
- Testing, maintenance, and version control processes
How often should we test the disaster recovery plan, and what types of tests are recommended?
Test at least annually; higher-risk or rapidly changing environments should test more frequently (quarterly or after major changes). Recommended test types:
- Tabletop exercises (walkthroughs of procedures)
- Partial technical tests (restore a subset of systems or data)
- Full failover tests (simulate complete switch to DR environment)
- Failback tests (return to primary environment)
After every test, document findings, fix gaps, and update the plan.
What backup strategy should we use to meet RTO and RPO requirements?
Choose backups based on RTO/RPO: for near-zero RTO/RPO use synchronous replication or active-active clustering; for short RPOs use frequent snapshots or asynchronous replication; for longer RPOs use daily incremental/differential backups. Ensure:
- Offsite or immutable backups (to mitigate ransomware)
- Encryption in transit and at rest
- Regular restore verification
- Retention lifecycle aligned with compliance and business needs
Who should be involved in the disaster recovery process and how do we ensure roles are clear during an incident?
Involve IT operations, security, application owners, business/unit leaders, facilities, legal/compliance, communications/PR, and executive sponsors. To ensure clarity:
- Define and document roles & responsibilities in the plan
- Create an incident command structure (incident commander, technical leads, communications lead)
- Maintain an up-to-date contact roster with backups for key roles
- Train stakeholders on their responsibilities and run periodic drills that exercise decision-making and communication paths