Stress testing is a process used to know how a software or system or any component behaves when conditions are extreme. The goal of stress testing is to recognize the limits of the software, and to learn about any potential failures that could occur in the system under extreme load or huge traffic. This process is commonly used in the world of software engineering to test the stability, quality, and performance of software systems.
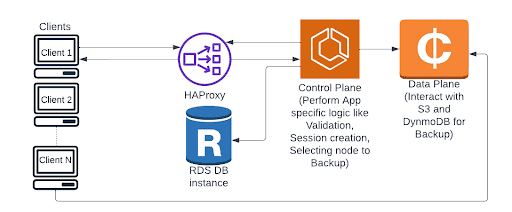
At Druva, we have created a stress-testing environment for validating the backup load. This setup simulates the production load and validates how our system behaves when there is heavy traffic and load.
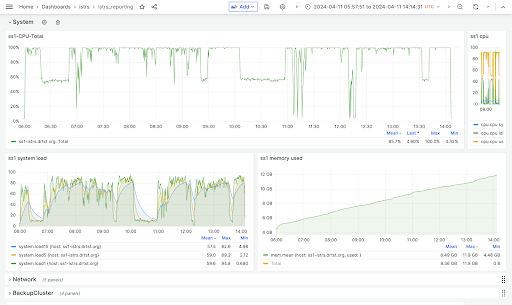
In Druva, we have containerized architecture. We have a set of Amazon ECS clusters with multiple Amazon EC2 instances. Amazon Web Services (AWS) offers various Amazon EC2 instance types, and adopting them for production requires thorough validation. With this stress setup and the metrics in place, we can qualify the suitability of different instance types for production environments. By analyzing performance metrics, such as CPU usage, memory usage, and IOPS, we can assess the capability of each instance type to meet the requirements of our production workload. This validation process helps ensure that the chosen instance types can effectively handle the workload demands and provide the required performance and reliability.
This stress test serves several purposes in achieving our goals. For example:
Application Changes
Validating backup orchestrator workflow-related code modifications.
Introducing a new application layer.
Improving performance, and load handling. For example - Improving a DB query.
Infrastructure Changes
Upgrading container OS versions.
Upgrading third-party components like the HAProxy version.
Adopting a new Amazon EC2 instance without impacting any existing architecture/workloads.
Packages and Library Upgrades
Validating SSL, cryptography, and Python upgrades.