Implementing the Pre-Restore Scan Feature
Trigger points and frequency for data restore requests are very sparse over a period of time and hard to predict. This makes it impossible to right-size the infrastructure needed to run the pre-restore malware scan operations we were interested in.
So we devised an on-demand infrastructure-based approach to provide predictable RTO (Recovery Time Objective) by paying for the infrastructure only when it is needed and getting used. Here’s the sequence of steps that the scan job follows.
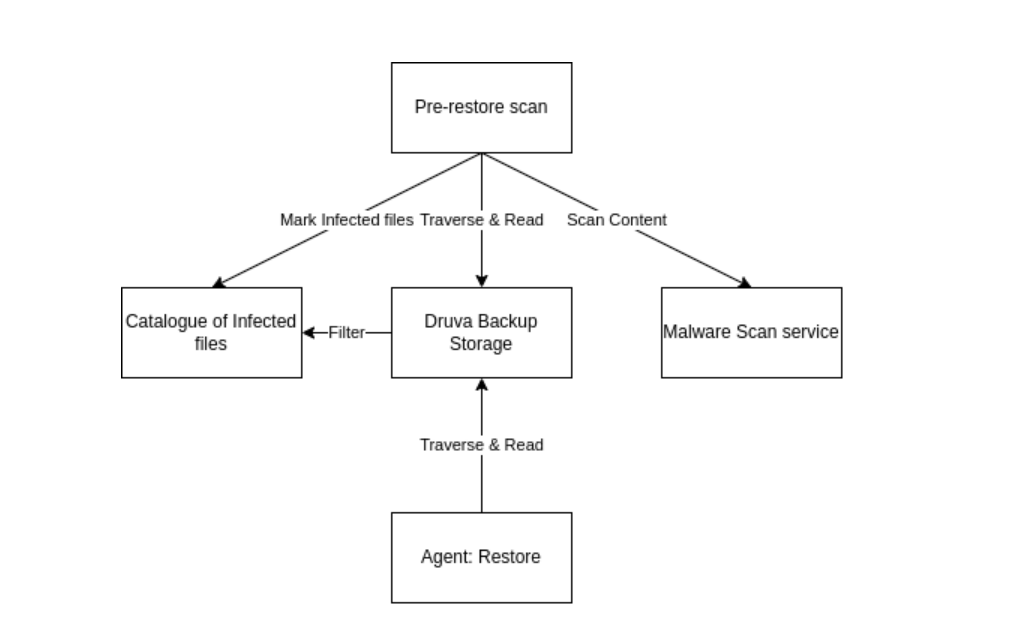
The malware scan job is triggered when the user initiates a restore operation.
The job reads the content of each file marked for restoration from the Druva backed-up data storage.
The file contents pass through the malware scanner.
Based on the scan outcome, each file is tagged as clean/infected.
Depending on the size of the data set, the scan job duration may vary from a few minutes to multiple hours. The scan job is scheduled by a homegrown load balancer that is purpose-built for long-running jobs.
The load balancer uses a fleet of AWS spot instances which are allocated based on need. The load balancer ensures that it spawns spot instances and makes capacity available whenever needed. With this, be it a regular day with hundreds of restores, or high-traffic scenarios of thousands in less than an hour, the scaling requests get handled in a predictable manner.
Druva products store backed-up data in a proprietary storage structure (refer to Druva documentation for more details). This data is accessed for malware scan operation via APIs hosted by the storage services. These APIs accept file identifier information (file path and point-in-time snapshot for backed-up data) and return the file data back. This kind of API access provides an easy and flexible means to consume data and operate on it.
Malware scan is deployed as a scale-out service. It embeds an off-the-shelf scan engine which is responsible for scanning the file content and identifying whether it has traces of malware. The service provides a simple REST API to accept file content as part of the request and gives out the label (clean/infected) as a response.
A simple CPU utilization-based scaling policy ensures that the infrastructure needed for malware scan scales up whenever a scan job starts.
Finally, the catalog of clean and infected files in the context of a particular restore job is prepared and stored based on the scan outcome for individual files. This catalog is stored in the NoSQL database: AWS DynamoDB. The catalog serves multiple purposes. It is referred to during the data restore operation to figure out whether it is safe to fetch the data and present it to the user. The catalog is also used to build a report that provides insights to the user on malicious files found in the backed-up data.
After the scan workflow completes for the selected data, the usual data restore operation is initiated. During restoration post malware scan, the service checks the labels present in the catalog and makes sure that files marked as infected are dropped. This end-to-end workflow ensures that only clean and safe data is restored. Once the restore job completes, users can download a report highlighting the infected files that were dropped.
The workflow ensures that it is simple and easy for users to complete the task on their own. All that users need to do is to choose whether a pre-restore scan is needed when they trigger a regular data restore job.
With the adoption of services with robust APIs, Druva managed to build the pre-restore functionality and integrate it with recovery workflows for multiple workloads such as file servers, network attached storage (NAS) shares, and devices (laptops/desktops).
Takeaways from Implementing the Pre-Restore Scan Feature
Having the ability to launch infrastructure on-demand to start data scan activity is crucial. It helps keep costs in check as infrastructure is requested and paid for only when it is getting used. At the same time, it ensures that the job starts immediately providing a good RTO.
Malware scan tools traditionally work on files stored on local storage. This limits the options available for integration and scale. Druva needed integration with these tools as part of cloud-native applications. Deploying it as a RESTful service made it easier to integrate with various types of consumer services. Additionally, it ensured that the service scales on demand, and consumes resources only when required.
Services with robust APIs help engineering teams implement functionality that can be leveraged and integrated with multiple workflows.
Next Steps
To learn more about Druva’s technical innovations and how we deliver the best cloud-based backup and restore solution on the market, visit the tech/engineering section of the blog archive.