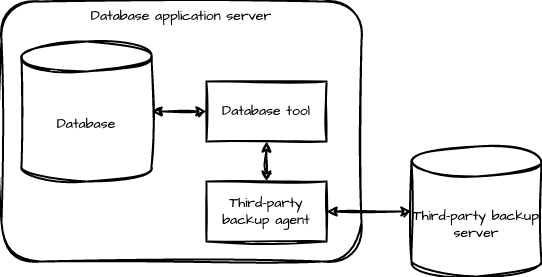
Responsibilities of the Data Mover for Push Stream-based Workloads
Back up files to the cloud storage by accumulating the incoming data blocks.
Back up file metadata and attributes to the cloud storage.
List all the versions of a file present across multiple snapshots on the cloud storage.
Fetch the details of a specific version of a previously backed-up file.
Restore a specific version of a file from the cloud storage.
Manage concurrency during backups.
Manage stats during backups and restores.
Need for Accumulation of the Data During Backup
For push stream-based workloads, the application itself orchestrates the backup using its native backup tool. The Druva agent for such workloads primarily focuses on two tasks during backup:
Reading the blocks from the stream where the application is pushing the data and uploading those blocks to the storage using the data mover. (The size of the blocks that are read from the stream is controlled by the agent. There can be different sizes during the tenure of the backup.)
Determine the size of the block that should be uploaded to the storage from the set of block sizes supported by the storage.
The configurable nature of the size of the blocks helps in achieving high throughput and low network latency during the backup. But it also means that the size of the blocks the data mover receives from the agent, and the size of the blocks the data mover needs to upload to the storage, may vary depending on the configurations set by the agent for these two tasks. To address this, the data mover accumulates the incoming data blocks from the agent and uploads them to the storage when the pre-decided upload size is reached.
How is the Data Accumulated?
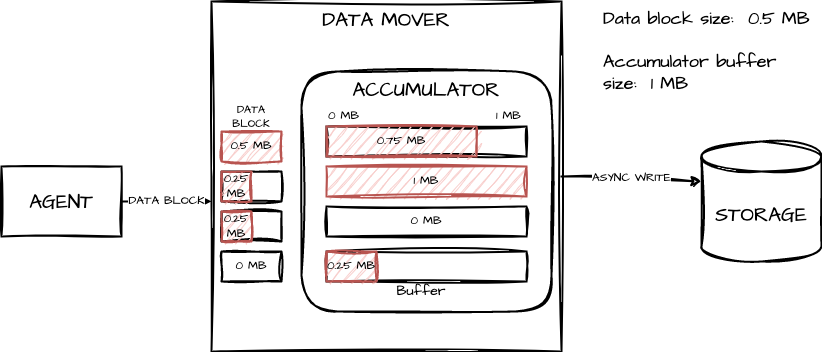
The accumulator component in the data mover is responsible for data accumulation. The data mover maintains a thread-safe cache of the file handle and its accumulator. The accumulator allocates a buffer to accumulate the data received for the file. The accumulator keeps a virtual and actual offset to track and maintain the block alignment between the local buffer and the cloud storage.
When the accumulator receives a data block, it checks the offset of the block against the virtual offset. The accumulator will detect and prevent non-sequential writes and will pad the buffer whenever necessary to maintain the virtual block alignment. At any point, if the allocated buffer is full, the accumulator will upload the buffer to the storage and allocate a new buffer. Finally, when the block offset is equal to the virtual offset, the accumulator will perform the following operations:
Calculate the size that can be copied to the buffer.
Depending on the size of the block, either add the entire block to the buffer or split the block into two chunks.
Add the first chunk into the buffer, and increment the virtual offset.
Upload the buffer to the storage using the storage API, and increment the actual offset.
Allocate a new buffer.
Repeat this entire process for the other chunk.