Introduction
Schedulers help us to run jobs and tasks at specified intervals. At Druva, we use schedulers for automated backups, to trigger user-defined backup schedules, and to track several background activities. Schedulers enable us to separate our business logic from time tracking.
However, our existing implementation of schedulers was causing CPU spikes and affecting the performance. We wanted something that could trigger schedules in a staggered manner. This blog explains in detail the problem we had, our scheduler requirements, how we designed it, and finally its performance.
Challenges with existing schedulers
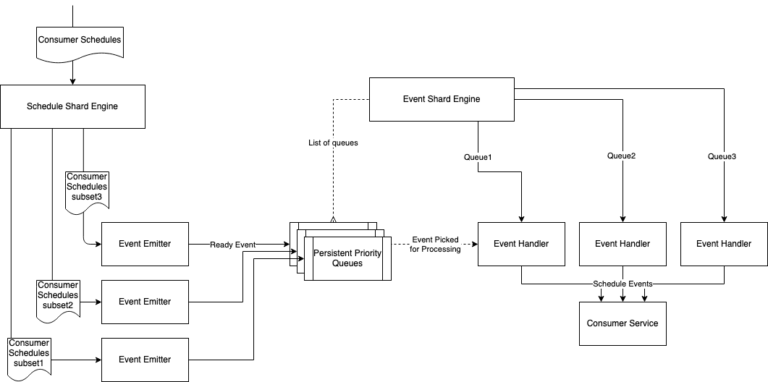
In the initial phases of the product, different teams used different scheduler implementations to meet their specific needs. But with Druva’s fast-growing customer base, existing schedulers started hitting their limits such as inability to handle spikes, lag in triggers from the desired time, high cpu/mem during load/reload activity, and so on. Thus, the product team decided to adopt a common solution that can be used across all Druva products.
During requirement gathering, we observed that in addition to simple cron schedules (schedules that are triggered at a particular point in time) there are many scenarios where we need scheduled batch processing. Scheduled batch processing means that we have a batch to process within a defined time window. Although we don’t need to start processing every item at the start of the window, we should complete processing the whole batch within that window.
In our existing implementation, we created schedules for every item in a batch with the window start time as the trigger time for all those schedules. This resulted in a CPU spike on the consumer at the start of the window. This was impacting the overall performance of the consumer service. It would have been great if the scheduler could send triggers in a staggered manner.
Such schedulers could be used for cron schedules as well. Cron schedules would be a special case where staggering (throttling policy) will not be applied.
Managing the load on the consumer due to triggered schedules is never the responsibility of the scheduler. We could not find any off-the-shelf scheduler that can cater to this specific requirement of scheduled batch processing. Thus we decided to build such a scheduler in-house.
Our scheduler requirements
- The scheduler must be stateless, scalable, and a consumer-independent service.
- The scheduler should support schedule triggers via SQS events or HTTP callback.
- The consumer must be able to create a cron-like-expression based schedule that can be associated with a particular timezone.
- The consumer must receive triggers as per the timings identified in its cron expression.
- The consumer should be able to define an event (schedule trigger) count n for a schedule. The scheduler should trigger n unique events on the consumer whenever the schedule is triggered. For cron schedules, it will be 1, but for schedules created for batch processing, the number can be set to the batch size.
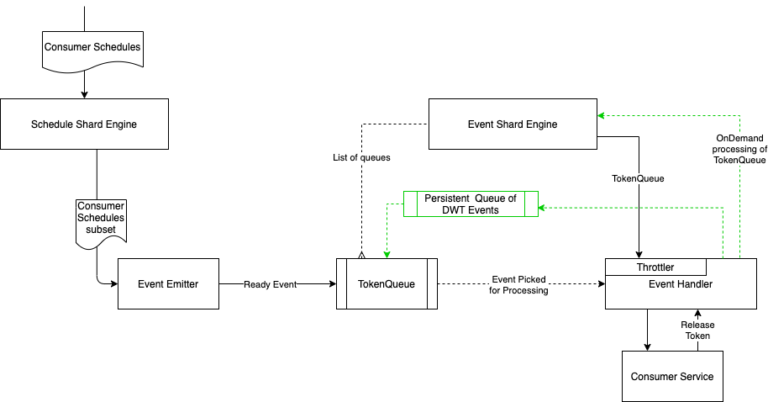
- Finally, the consumer should be able to define the throttling policy. The policy will define the maximum number of events that can be triggered on the consumer at any given point in time. This limit will be applicable to events across all schedules where this policy is applied.
Components of the scheduler
Schedule Master
This component will manage the consumer service defined entities. The scheduler master exposes the Rest API to manipulate these entities. The primary entity is ScheduleJob as described below:
ScheduleJob
Represents schedules based on cron like expressions. For example:
{
“Month”: “*”
“DayOfMonth”: “*”
“DayOfWeek”: “*”
“Hour”: “3,6,9”
“Minute”: “*”
}
This expression represents 3 triggers every day at 03:00, 06:00, and 09:00.
Whenever a consumer defines any ScheduleJob, along with that scheduler, it creates another type of backend entity instance called ScheduleChild. Every child entity has 2 attributes viz. LaunchExpression and Minute. These 2 attributes combined create one trigger that is represented by the cron expression. Thus for the above schedule, 3 children will be created for everyday triggers at 03:00, 06:00, and 09:00.
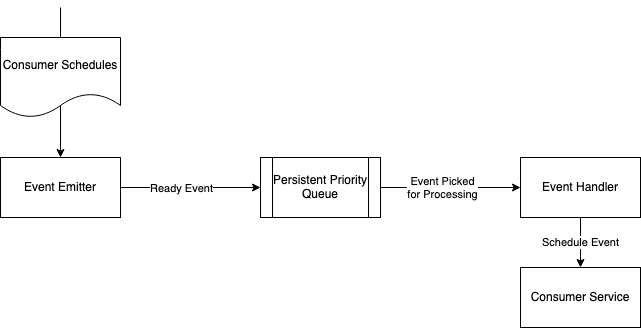
Schedule Event Emitter
This is the backend component that acts as a schedule scanner. It runs periodically and scans upcoming schedules. For all such schedules, it then creates Schedule-Events. Every event will have LaunchTS associated with it and will contain all the info required to trigger the schedule. These events are added to the event queue which is then processed by the next component.
EventHandler
This is also a backend component. It scans Schedule-Events emitted by the emitter. It also runs periodically to pick events due for trigger in the next few minutes.
Design of the scheduler
At its core, the scheduler can be thought of as a collaboration of 2 scanners running periodically viz. schedule scanner (emitter component) and event scanner (event handler component).
The schedule scanner runs periodically for a particular scan window. The scan window is the time interval between 2 consecutive runs of the scanner. It picks scheduled children having their trigger time in its scan window. For every such schedulechild, n events with unique IDs are created and pushed to the event queue (a priority queue).
The event scanner runs every m minutes (our duration was 5 minutes). It picks events having LaunchTS in the next m minutes. Every event that is picked is handed over to some worker. Events will have all the details required for processing including schedule ID and SQS details provided at the time of schedule creation. In other words, event processing is independent of the original schedule for which the event is created. On reception of the event, the worker goes to sleep till the exact trigger time of the event occurs. At the trigger time, the worker wakes up and sends the event to the appropriate SQS or HTTP endpoint. Once the event is triggered successfully, it will be moved to a special event queue named D (Done queue).