In part 1 of this blog post, we learned about FLR, its significance, and the solution that we built to make VM file restores easy and less resource-intensive.
In part 2, we will discuss the improvements we made in the FLR restore process to achieve faster execution speeds.
But, before that, here’s the tech stack and key terms that we will use frequently throughout the blog.
Technology stack that we used
Language: Python
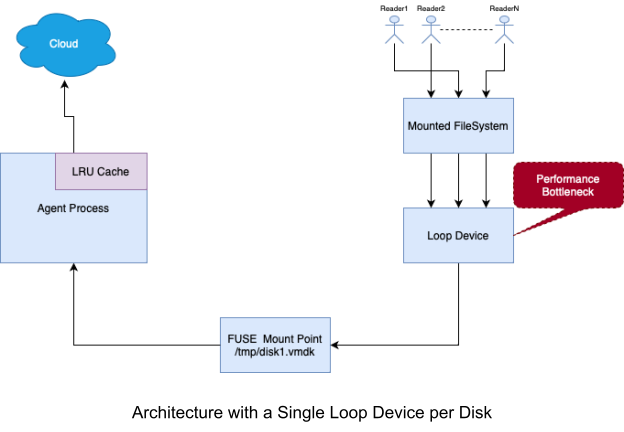
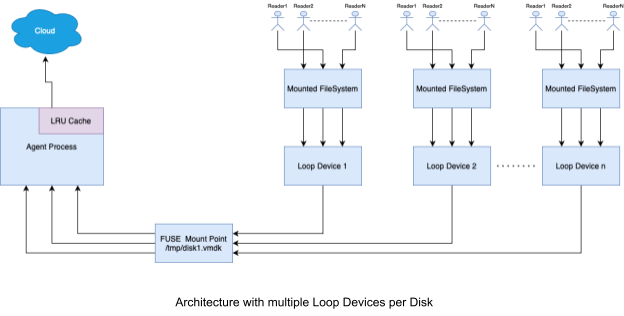
FUSE: User module implemented with Python
Loop Devices
Terminology
FLR: File-Level Restore.
Virtual disk: A virtual disk is a file that appears as a physical disk drive to the guest operating system. Virtual hard disk files store information, such as the operating system, program files, and data files.
Disk Offset: An offset into a disk is simply the character location within that disk, usually starting with 0. Thus, "offset 240" is the 241st byte in the disk.
File Offset: An offset into a file is simply the character location within that file, usually starting with 0. The important thing to note is that a File Offset is converted to a Disk Offset before the data can be read – this conversion is done by the underlying FileSystem.
Target/Target VM: Used interchangeably to refer to a target virtual machine where data has to be restored.
Download Chunk: Data at a particular file offset that is not yet downloaded/read from the cloud. It is defined by the tuple of filename, offset, and length:
Filename: The file to be read.
Offset: Denotes the location of the character within the filename of the file from where the data has to be read. Note that this is a file offset which is converted to disk offset by the mounted file system.
Length: Length of data to be read starting from the offset.
Upload Chunk: Data at a particular file offset that has been downloaded from the cloud but is not yet uploaded/written to the target VM. It is defined by the tuple of filename, offset, length, and data:
Filename: The file to be written.
Offset: Denotes the location of the character within the filename from where the data has to be written.
Length: Length of data to be written starting from the offset.
Data: The data to be written.
Reader/Writer Pipeline
The InitiateFileTransferToGuest API reads from the source and writes to the target. However, the API does not provide any control over the following:
Number of threads used to read/write data
How much data is read at once
How much data is written at once
Essentially, we don’t have any information about InitiateFileTransferToGuest API’s internals. However, we did know that it is not very performant, at least in our case. We wanted to have more control over how data is being read from the source and written to the target.
To workaround this issue, we implemented our own reader/writer pipeline. To support this new implementation, we injected an executable in the target VM using InitiateFileTransferToGuest API. This executable starts a rest server in the target VM and exposes REST APIs to write data to a file. We will now be using this new API to write data to the target VM.
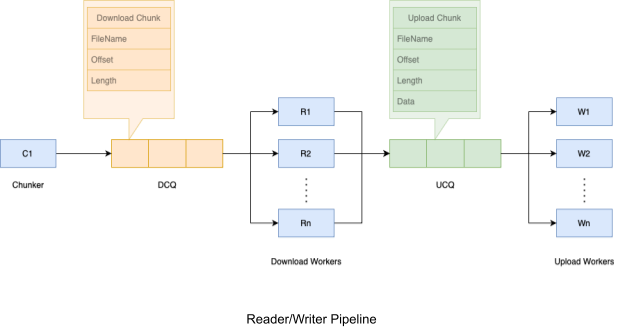
The Pipeline
There are two queues:
Download Chunk Queue (DCQ): A FIFO queue for the download chunks
Upload Chunk Queue (UCQ): A FIFO queue for the upload chunks
There are three groups of workers that work together on the above queues to read files from the cloud and write files to the Target VM.
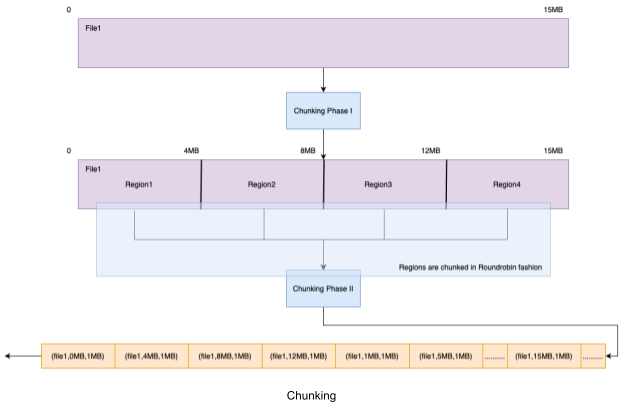
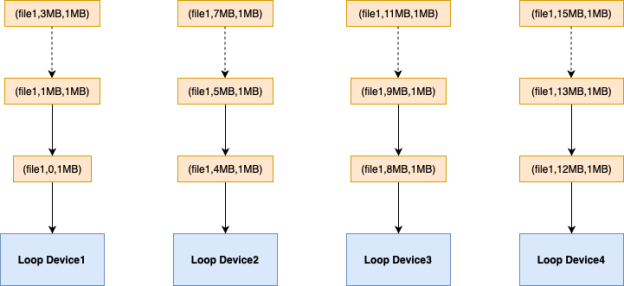
- Chunker: Divides a file into 1 MB Chunks and adds to DCQ (Download Chunk Queue). The last chunk of the file may be smaller than 1 MB.
- Download Workers: Pick up download chunks of the file from DCQ and issue read requests. Once the chunk has been downloaded, add it to UCQ.
- Upload Workers: Picks up upload chunks of the file from UCQ and uploads them to the target VM.