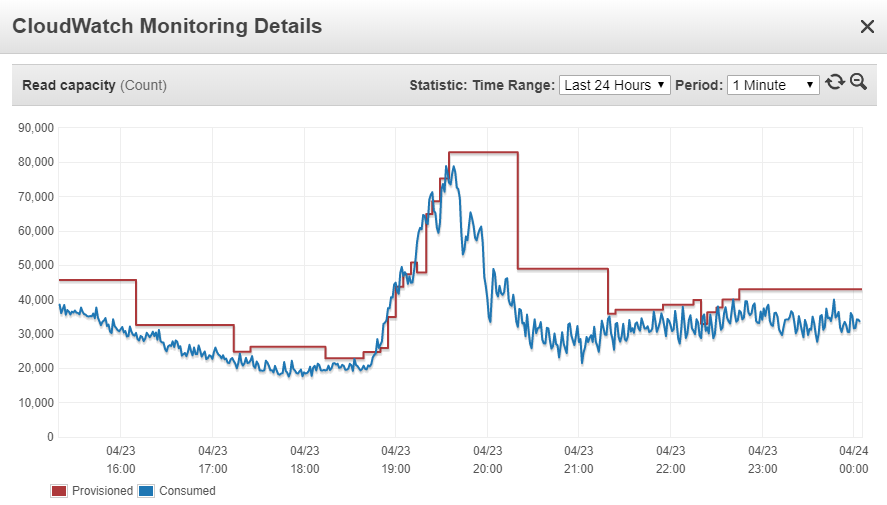
Example of DynamoDB provisioning
A DynamoDB database is called a table, which stores multiple key-value pairs. Each key is uniquely identified by a combination of partition-key and range-key. The partition-key is mapped to a physical partition and range-key identifies the item uniquely within that physical partition.
Provisioned capacity is separate for reading and writing I/O operations and is equal to the number of operations of a given type that can be successfully serviced by the DynamoDB backend per second.
Consumed capacity is the actual number of I/O operations of the given type (read or write) that are requested per second.
In the case that consumed capacity exceeds the provisioned capacity, the excess requests may fail and are called as throttles or failed requests that should be retried at a later time. In such an event, the best option is to retry the request after a certain wait time, where the wait time is increased exponentially for each subsequent retry. This approach is called exponential retry logic and is supported by many SDKs.
The need for custom DynamoDB tuning
DynamoDB throttles can cause delays in application requests due to the time spent in retries and may even result in request failure if all retries are exhausted. Thus, sufficiently provisioning DynamoDB capacity to avoid throttles is essential.
Another reason for DynamoDB throttles even with sufficiently provisioned capacity is due to thin partitioning. To understand this better, let’s dive a bit deeper into the workings of DynamoDB internals:
- DynamoDB guides the application to uniformly distribute the keys as follows:
- Uses a wide range of partition-keys
- Stores approximately equal number items with the same partition key value
- The above ensures that the physical partitions are uniformly utilized and that the provisioned capacity can be used most effectively.
- For example, if the table has 10 physical partitions and the provisioned capacity is 10K IOPS, then 1K IOPS is the effective provisioned capacity for each physical partition
- As a result, if the application has an unequal distribution of items to each physical partition, there will be throttles even with sufficient provisioning.
Another major challenge in using DynamoDB is the use of hotkeys. For example, if a single key is read 10K times per second, it will result in throttles since it resides in a single, physical partition which is provisioned by only 1K IOPS.
Last but not the least, the time required to change the provisioned capacity is the matter of a few minutes, which may or may not be tolerated based on the nature of the application.
Trend-based DynamoDB tuning
A few years back, DynamoDB throttles were a serious problem for Druva and the impact was potential backup failure or other task failures due to provisioned throughput error. Throttles and task failures increase at the start of work hours. This happens due to a sudden surge in the number of backup tasks starting, increasing the consumed IOPS.
Reaction-based provisioning increased strategy is not sufficient in such cases as it takes around 5 minutes for the increase in provisioning to take effect.
The solution designed to mitigate this problem is a trend based DynamoDB tuner. This tuner avoids the time lag in increasing provisioning with respect to consumption as follows:
- Maintaining consumption trend information of each DynamoDB table for the past 4 weeks.
- At 30 minute intervals, for the same day of the week and at the same time, the past consumption values are obtained.
- Based on the past trend, a median of DynamoDB consumption is calculated — named as consumption-trend.
- A concept called a trend-multiplier was also invented to keep an appropriate gap between provisioning and consumption, to avoid throttles.
- Provisioned capacity is set 15-30 minutes in advance for the given time of the day as consumption-trend/trend-multiplier.
This tuning strategy allows minimizing the throttles at all times, except in the case when trend-based prediction and actual usage patterns differ. In such an event, reaction-based tuning is the only option.
COGS-efficient DynamoDB tuning
Over the years, DynamoDB has evolved and the number of throttles has significantly reduced. With that, Druva received an opportunity to save COGS (cost of goods sold) by changing our provisioning strategy.
AWS also has its own auto tuner, which is purely consumption-based. It does not react to throttles, which is the main reason we needed to provide our own tuner. Although infrequent, the thin partition and hotkeys have still caused throttles sometimes.
COGS optimization can be achieved through the following:
- Reduce the multiplier based gap between consumed and provisioned IOPS by provisioning less when there are no throttles. If the default multiplier is 1.2, provisioning is 20% more of consumption. By reducing the multiplier to 1.1, 10% savings on COGS can be achieved.
- Save COGS by eliminating the multiplier based logic completely for highly provisioned tables. For example, if a DynamoDB table consumes 100k, then provisioning 10K extra IOPS because of the 1.1 trend multiplier value results in significant costs. For such tables, the gap between consumed and provisioned IOPS can be reduced even further, by having a constant gap for consumption slabs.
The tuning criteria:
1. Increase provisioned IOPS (Input-output operations per second) in response to an increase in consumed IOPS based on the following formula:
- New provisioned IOPS = min (new consumed IOPS * iops_multiplier, new consumed IOPS + iops_gap_for_slab)
- Below is a table that reflects an example of consumed IOPS slabs and corresponding gaps:
| Consumed IOPS | IOPS gap |
| 0 to 20k | 1k |
| X k to 2X k | X/10 k |
| 200k and above | 10k |
2. Decrease provisioned IOPS every 15 minutes (or configurable time interval) if consumed IOPS have dropped so that the gap between consumed and provisioned is more than the recommended gap + margin for that IOPS slab.
3. Increase provisioned IOPS in response to throttles below:
- Ignore all throttles below tolerable throttle percentage
- If throttles are above tolerable throttle percentage
4. New provisioned IOPS = current provisioned IOPS * (1 + throttle percentage)
Conclusion
Custom DynamoDB tuning has certainly benefited Druva and has helped optimize performance as well as reduce TCO. The recommendation for DynamoDB users is to pick a tuning strategy that is most suitable for the use case at hand. In some cases, a hybrid approach may also be beneficial. It is also important to weigh the complexity of implementing a custom tuner versus the actual benefits and then choose an appropriate strategy.
Learn more about how Druva has built a metadata-optimized backup architecture in the cloud.