Druva provides the backup and restore of data to and from a variety of data sources (cloud apps, file servers, NAS, SQL servers, etc.), varying in magnitude as well as complexity. In our quest to serve our customers better, we are continuously striving for technologies which can make our core pipelines of backup and restore flexible, fast, and efficient.
Motivation and requirements for porting our core pipeline
Agent is an executable running on a customer’s device which is responsible for the backup and restore of data to and from the Druva Data Resiliency Cloud. Existing Druva agents are written in Python/Golang, and utilize the power of asynchronous programming (a form of parallel programming) to speed up operation for its specific workload.
However, one thing common across all agents is the complex data pipeline transporting data and uploading it to the Druva Cloud, and vice versa for restore.
We thought of carving out this common piece of complex data pipeline and bundling it as a library that will be utilized by our agent. This is the core of our agents and we want it to develop a data pipeline with the following features:
- Performant in terms of network IOPS
- Scale with the device resources (CPU/Mem)
- Bindings for Golang/Python
- Mature library support of asynchronous programming
- Cross-platform support
- Preferably no garbage collection as we want tighter control over resources
Reasons for selecting Rust
The Rust language caught our attention and we chose it for the following reasons:
- Non-garbage collected (which means much tighter control over resources)
- Close to C performance (comparison)
- Compile to native object code
- Easily compiles down to a shared library, allowing source-less distribution of the SDK (Software Development Kit), along with C-API (C-based Application Programming Interface) support
- Very strong safety guarantees (compared to C and C++) for memory, and highly concurrent code
- Built-in support for asynchronous programming
Challenges with adopting the Rust ecosystem and its solutions
Buffer copying
Python and Golang are Garbage Collected (GC) languages, meaning memory is released automatically for the allocated objects which are not in use by any part of the program. Rust is a non-GC language, meaning the memory of the allocated objects needs to be managed explicitly by the code.
The problem with interfacing the GC and non-GC runtimes is when data crosses the language boundary it needs to be copied. This is not a problem for primitive data-types, but for large buffers, such as our core data pipeline, it becomes a problem.
Solution:
To solve this problem we relied on the Rust layer for allocations and deallocations of memory. The Go/Python layer allocates the memory by calling the APIs of the Rust library, it then fills up the allocated space buffer with data through the Rust library API calls. Once the data is uploaded to the Druva Cloud, the allocated space can be freed by calling the API of Rust library. In this way, memory management lies completely on the Rust layer, buffers need not be copied, and Python and Golang layers are free from cleaning the garbage memory.
Pressure on the OS due to system threads
This problem is particularly for the Golang, as Python typically uses a single thread due to Global Interpreter Lock (GIL). In Golang, any system call spawns a system thread. Golang mitigates this by reusing already spawned threads as much as possible. But if N requests are to be made to the Rust layer, then N threads will be spawned — this N can reach an excess of 500 as well. Multiple such processes could exist on the same host and it might put pressure on the OS.
Solution:
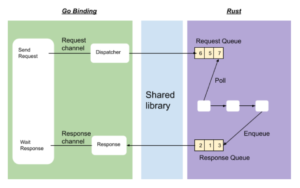
To mitigate this issue, we treated the Rust layer as a Remote Procedure Call (RPC) server and Golang layer as an RPC client. The interface is then modeled on RPC-style request/response. Each request, having a unique ID, will be enqueued to a channel. The other end of the channel dispatches requests to the Rust side. This dispatcher will actually call the Rust library API, which means a system thread will be spawned. However, in this case only one thread per dispatcher will be spawned.
Once the request is handled, the pipeline will enqueue it to a queue from which a receiver go-routine will poll. Using the request ID, the receiver will send the response to the appropriate go-routine.
The effect of this is that the Go side can spawn many go-routines without incurring the system thread penalty. There can be multiple dispatcher and receiver go-routines to scale a high number of requests.