
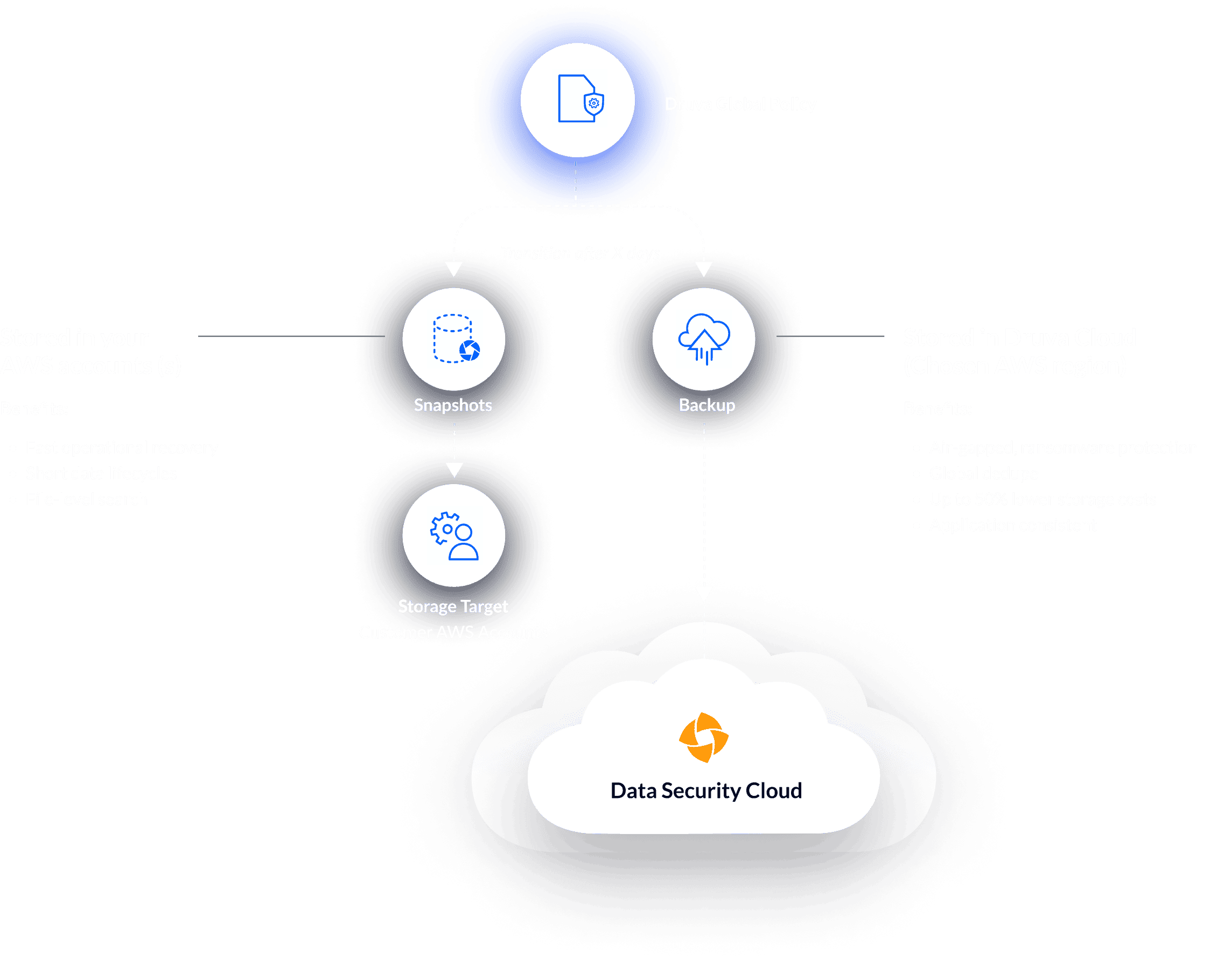
Silo-free cloud data protection
Eliminate data silos through centralized data protection management and improve visibility across cloud native apps and non-hosted databases in public clouds.
Lower your TCO
Lower TCO costs compared to native snapshots with global deduplication and compression of data while eliminating egress fees.
Reduce data risk
Defend against ransomware with secure, immutable snapshots. Restore backups into a new account if your production accound has been compromised.

“Druva streamlines management and gets us 100% visibility into all workloads, including hundreds of AWS accounts. We get maximum data protection control with minimal effort.”
Related Resources

Solution brief
With secure, air-gapped backups of Azure VM data, protecting against cyber threats at a lower cost and without management complexity.

Whitepaper
Remove the need for cross-account and cross-region snapshots and get secure, air-gapped backups against threats — all at half the cost of competitors.
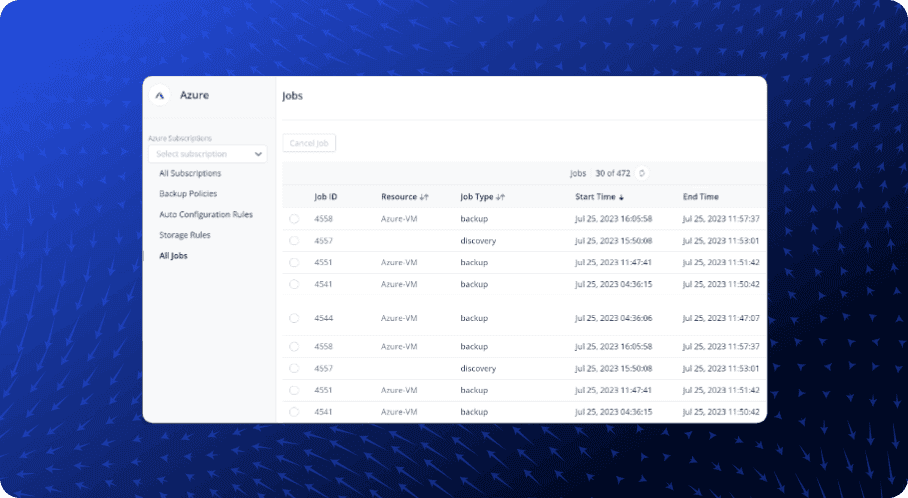
Demo
Watch the video to see how Druva can cut your risk of cyber threats and save on Azure VM storage costs.