The future of work is a big concern for companies of all sizes. The 9-to-5 office workday has given way to employees working remotely from multiple locations, and while there’s been plenty of discussion of work-from-home employees, the remote office/branch office (ROBO) often presents an even greater IT challenge.
According to Nemertes Research, approximately 90% of new hires today work in branch offices [link], yet only 20% of those locations have IT staff present to manage the significant IT assets required to run the location. Because IT staff is handling data protection remotely as part of a portfolio that can be described as supporting “everything with a plug in it,” data protection often takes a back seat, putting the organization’s data at serious risk.
The unique challenges of remote office data protection
Issues with ROBO data aren’t uncommon: According to research by Enterprise Strategy Group (ESG), 37% of companies reported local data backup as a significant challenge. The problem has many facets, and any one of them can put an organization at serious risk.
- Lack of resources — When the remote office lacks trained IT staff, and especially when network connectivity is limited, data protection is too often neglected. This problem is especially challenging when remote offices are based in different countries than the head office, each with different local regulations.
- Manual processes and human error — In many cases, data backup processes rely on multiple people carrying out the right steps manually, such as collecting tape-based backups and shipping them off-site. This opens the door to human error, putting the organization’s security at serious risk.
- Lack of visibility into backup success — Organizations need to test that backup is actually working as intended to identify and address problems. Full tests of data backups are challenging enough for an IT team, and asking non-IT staff in a remote office to carry out this task is impractical, if not impossible. As a result, the organization doesn’t have clear visibility and doesn’t know whether their data is protected until it’s too late.
- Compliance oversight challenges — Companies of all sizes can be involved in legal issues and may end up needing to provide specific data to the courts. Without the right storage and index procedures, it’s possible for requests to be mishandled or data to be irretrievable. It’s a recipe for expensive, time-consuming work, and potentially puts the organization at legal risk.
- The growth of ransomware — Ransomware attacks encrypted files then demands payment for unlocking them. ROBO locations are particularly vulnerable when shared file servers are involved and local IT staff are not on hand to help employees avoid attacks.
While organizations may have well-defined data protection policies that are enacted centrally, implementation at ROBO locations is often lacking. The unique challenges of managing data security at these locations too often result in inadequate backup procedures that put the organization at risk of data loss and regulatory non-compliance.
Rethinking data protection for distributed environments
To solve these problems, organizations must reconsider the entire environment, not just individual parts. For example, individual server backup may work well for a small organization in a single office, but it becomes inefficient when spread across multiple sites. Similarly, using tape-based backup is challenging when you don’t have the highly skilled staff resources to run this process correctly from end to end.
For many organizations, it makes sense to consider a cloud-based service instead. As wide area networks (WAN) have become more reliable and bandwidth has become less expensive, cloud solutions have grown as a scalable, cost-effective backup method. However, effectively protecting the growing amount of data that exists at remote and branch offices requires a shift in strategy.
For many organizations, it makes sense to consider a cloud-based service instead.
Today’s approach: from cloud-enabled to cloud-first
Rather than replicating older disaster recovery models on the cloud, IT should consider systems that are purpose-built built to take advantage of how cloud services are designed. For example, a true cloud-first approach will avoid proprietary cloud infrastructures where data can only be saved to a few specific locations. Similarly, IT shouldn’t have to install multiple systems or appliances in each new location but should instead leverage the simplified remote administration that can be achieved through the cloud.
There are many important considerations when approaching a transition from local data backup to a cloud-first solution. IT should be looking at how to make effective use of multi-tenant architecture alongside micro-services when examining a solution, whether it’s to be built or bought. Scalability is another important factor, as backup tends to create ever-multiplying volumes of data. Finally, a new approach that is designed to eliminate the risk of human error or local storage failure should be carefully investigated to ensure it doesn’t create any new single point of failure.
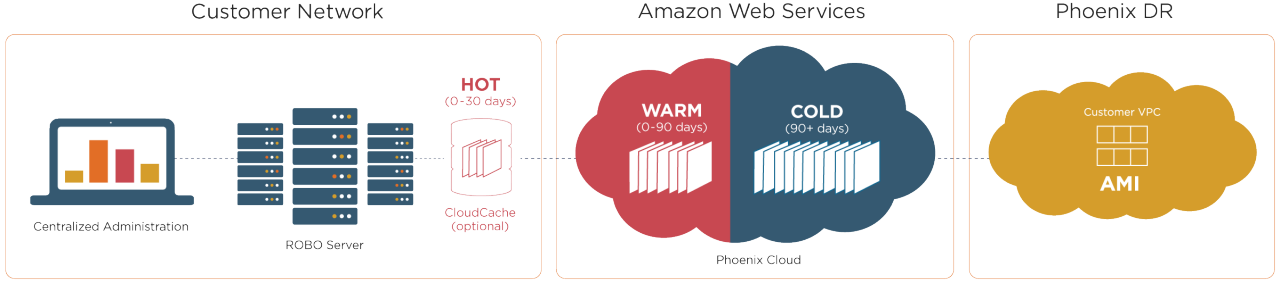
Cloud backup becomes even more cost-effective with storage tiering
Cost is an important consideration in any data backup strategy, and cloud-based backup makes it possible to tier data by priority to reduce overall storage costs. A good example is Amazon Glacier, which provides cheaper data storage in exchange for less immediate availability. New data is stored in a local cache or high-performance storage while it is likely to be retrieved frequently. After 90 days, the data is moved to long-term storage for archiving, reducing overall storage costs while still preserving the massive amounts of data necessary for legal compliance.