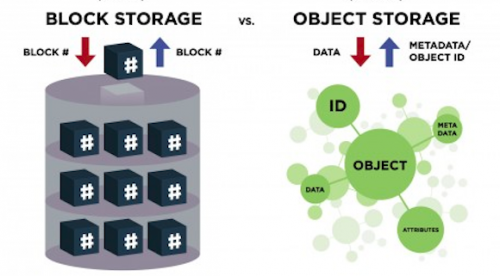
With block storage, files are split into evenly sized blocks of data, each with its own address but with no additional information (metadata) to provide more context for what that block of data is. You’re likely to encounter block storage in the majority of enterprise workloads; it has a wide variety of uses (as seen by the rise in popularity of SAN arrays).
Object storage, by contrast, doesn’t split files up into raw blocks of data. Instead, entire clumps of data are stored in, yes, an object that contains the data, metadata, and the unique identifier. There is no limit on the type or amount of metadata, which makes object storage powerful and customizable. Metadata can include anything from the security classification of the file within the object to the importance of the application associated with the information. Anyone who’s stored a picture on Facebook or a song on Spotify has used object storage even if they don’t know it. In the enterprise data center, object storage is used for these same types of storage needs, where the data needs to be highly available and highly durable.
Object storage generally doesn’t provide you with the ability to incrementally edit one part of a file (as block storage does). Objects have to be manipulated as a whole unit, requiring the entire object to be accessed, updated, then re-written in their entirety. That can have performance implications.
Another key difference is that block storage can be directly accessed by the operating system as a mounted drive volume, while object storage cannot do so without significant degradation to performance. The tradeoff here is that, unlike object storage, the storage management overhead of block storage (such as remapping volumes) is relatively nonexistent.
What problems does object storage solve?
Object storage is ideal for solving the increasing problems of data growth. As more and more data is generated, storage systems have to grow at the same pace. What happens when you try to expand a block-based storage system beyond a hundred terabytes or beyond multiple petabytes? You may run into durability issues, hard limitations with the storage infrastructure that you currently have, or your management overhead may go through the roof.
Solving the provisioning management issues presented by the expansion of storage at this scale is where object storage shines. Items such as static Web content, data backup, and archives are fantastic use cases. Object-based storage architectures can be scaled out and managed simply by adding additional nodes. The flat name space organization of the data, in combination with its expandable metadata functionality, facilitate this ease of use.
Another advantage to object storage its responsiveness to the need for resiliency while mitigating costs. Objects remain protected by storing multiple copies of data over a distributed system; if one or more nodes fail, the data can still be made available, in most cases, without the application or the end user ever being impacted. (Downtime? What downtime?) In most cases, at least three copies of every file are stored. This addresses common issues including drive failures, server failures, site failures, and power outages. The unique value for each object is also tied to its content, providing an easy way to check for possible bit-rot by recalculating the value and checking it against the original. Any corruption can be immediately addressed using one of the other independent copies. This distributed storage design for high availability allows less-expensive commodity hardware to be used because the data protection is built into the object architecture.
This is not to say that block storage systems do not also have resiliency features. Block storage systems offer RAID, erasure coding, and multi-site replication. The difference, however seems to be that these features were built into and assumed by object storage, where they were added onto block storage over time. Also, the more distributed your protection model is, the fewer block storage products you will find to support it. The opposite is true of object storage.
What about the tradeoffs?
Object storage has the potential to provide IT departments a great deal of value. It can save money in infrastructure costs by allowing the organization to use less expensive hardware, it can reduce management time through ease of scalability, as well as provide tremendous flexibility for certain types of storage needs.
But, as exciting as it sounds, object storage is not the answer to all your storage problems. Sometimes, block storage is a far better fit. There are use cases where object storage performs beautifully, scales out seamlessly, and solves all sorts of management headaches, but in other situations it outright fails to meet the needs of your application.
You have to decide which type of architectural approach is appropriate for your needs, as you balance the requirements for a scalable storage solution that provides resilience, performance, and usability.
Filesystems sitting on top of block storage excel in usability. The hierarchical structure of a filesystem (i.e. folders and subfolders) and the user-based naming convention of files (e.g. my-resume.doc) is a time-tested, well understood interface suited for direct user interaction. The completely flat structure and content-based identifier (e.g. 123e4567-e89b-12d3-a456-426655440000) of an object storage system is not well-suited for direct user interaction. This is why all attempts to connect users directly to an object storage system place a filesystem bridge between the two that gives a user the ability to name files and place them in directories, then converts them into objects. However, these “gateways” can be problematic and suffer performance challenges, leading one to wonder that if you wanted a filesystem, why didn’t you just use one?
The scalable resiliency of object also creates the challenge of deciding between eventual consistency and strong consistency. Eventual consistency is where the latest version of an object will be first stored on one node, and then eventually replicated to its other locations. Strong consistency would require the new version to be immediately replicated. The strongest consistency would be to delay the write acknowledgment until all copies had been successfully replicated.
Eventual consistency can provide unlimited scalability. It ensures high availability for data that needs to be durably stored but is relatively static and will not change much, if at all. This is why storing photos, video, and other unstructured data is an ideal use case for object storage systems; it does not need to be constantly altered. The downside to eventual consistency is that there is no guarantee that a read request returns the most recent version of the data.
Strong consistency is needed for real-time systems such as transactional databases that are constantly being written to, but provide limited scalability and reduced availability as a result of hardware failures. Scalability becomes even more difficult within a geographically distributed system. Strong consistency is a requirement, however, whenever a read request must return the most updated version of the data.
Technically, both object and block storage can do either eventual or strong consistency, but typically object storage uses strong consistency and object storage tends to use eventual consistency. Therefore, applications where eventual consistency brings value are typically best served by object storage, and those wanting strong consistency tend to prefer block storage.
Workloads for object versus block storage
Object storage works very well for unstructured data sets where data is generally written once and read once or many times. Static Web content, data backups, archival images, and multimedia (videos, pictures, or music) files are best stored as objects. Databases in an object storage environment ideally have data sets that are unstructured, where the use cases suggests the data will not require a large number of writes or incremental updates.
Geographically distributed back-end storage is another great use case for object storage. The object storages applications present as network storage and support extendable metadata for efficient distribution and parallel access to objects. That makes it ideal for moving your back-end storage clusters across multiple data centers.
Object storage isn’t recommended for transactional data, especially because of the eventual consistency model outlined previously. In addition, it’s very important to recognize that object storage was not created as a replacement for NAS file access and sharing; it does not support the locking and sharing mechanisms needed to maintain a single accurately updated version of a file.
Because block level storage devices are accessible as volumes and accessed directly by the operating system, they can perform well for a variety of use cases. Good examples for block storage use cases are structured database storage, random read/write loads, and virtual machine file system (VMFS) volumes.
Object storage in practice
Despite what some people suggest, object storage is not an emerging technology. Data stored as objects have already approached the exabyte scale (1000 petabytes) representing trillions of objects. Companies like Amazon (with S3) provide object storage via its public cloud platform at massive scale, while object storage can be implemented in the company data center using a variety of open source and commercial products.
When you begin to think about what types of items you should move into object storage, start with the low-hanging fruit. Take a look, for example, at low I/O workloads such as network share, which may be on a NAS device. In this instance, you are limited to the size of the unit. Without an easily expandable option, you are forced to overprovision in order to leave room for future expansion for the users, resulting in underutilization. By moving this workload to an object store, you’re not limited to the amount of space each unit holds. Nodes can be added easily within the object storage paradigm, allowing full use of the disks you purchased.
Regardless of the path you choose, it is important to familiarize yourself with the advantages and limitations of the architecture in order to get the most value for your company.