Figure 2: Batching
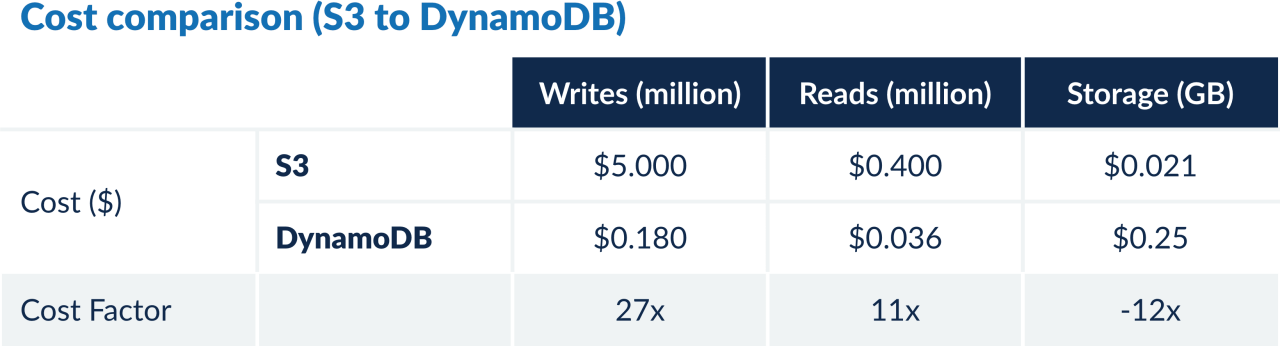
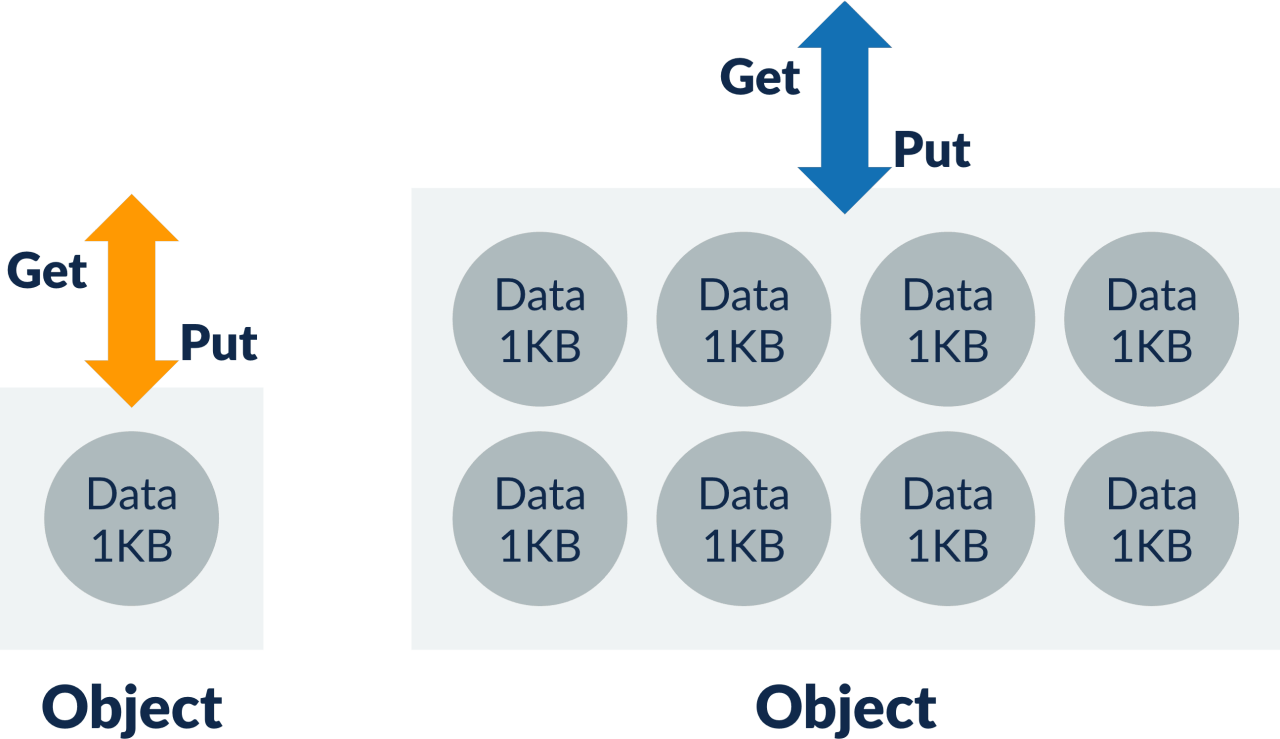
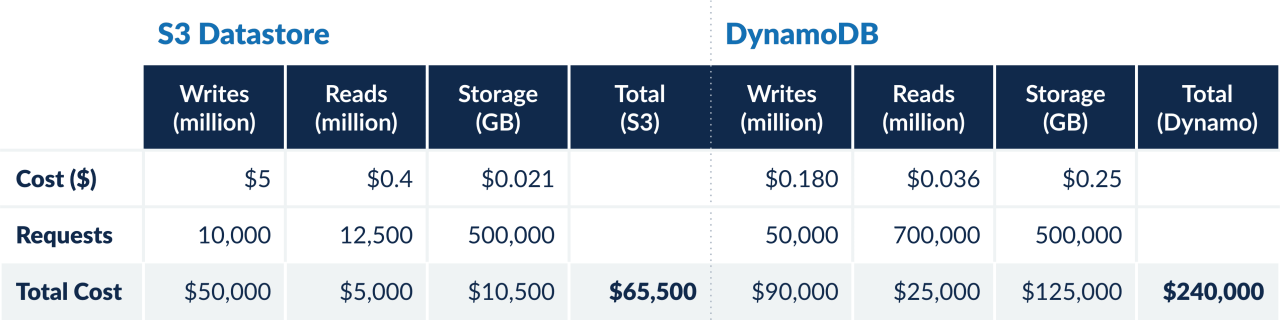
If we can batch 27 data units in a single S3 object, the IO cost will be equal to that of DynamoDB — the more the merrier.
Cost of S3 = ($5*X/N) + ($0.4*Y/N) + ($0.021*Z/N)
Where N = number of records batched in a single S3 object.
S3 — The database: S3 can serve higher throughput, thereby masking the effect of higher latency, especially for sequential access. The batching of multiple records in a single object further helps in throughput. But how can an object store be used as a database?
This is exactly the problem that Druva needed to solve; S3 had to become a database.
Potential savings: As mentioned earlier, Druva Data Resiliency Cloud performs frequent random data lookups to find duplicates, and needs a low latency storage for good performance. Some of the data operations need atomic access as well as the ability to perform conditional updates. These scenarios are supported by DynamoDB, and therefore, it’s best to keep such data on DynamoDB.
The infrequently and sequentially accessed data, like some metadata, is a good candidate to be moved to S3. Our access patterns suggested that close to 50% of the total contents from DynamoDB could be moved to S3. This would reduce the cost of DynamoDB by half.
DynamoDB = ($0.180*X/2) + ($0.036*Y/2) + ($0.25*Z/2)
At the same time, it will result into the cost of S3 as (assuming batching of 50 records):
Cost of S3 = ($5*(X/2)/50) + ($0.4*(Y/2)/50) + ($0.021*Z/2)
Since storage drove the overall cost, we were convinced about the savings. Further, our study showed 50 data units could be fit into a single S3 object, resulting in cost-effective IO access.
Implementation
Druva Data Resiliency Cloud protects petabytes of data from millions of devices, and the corresponding metadata is huge. To serve such large amounts of data, any database should be able to:
- Store and retrieve values efficiently
- Scale capacity on demand
- Scale performance on demand
- Be cost effective
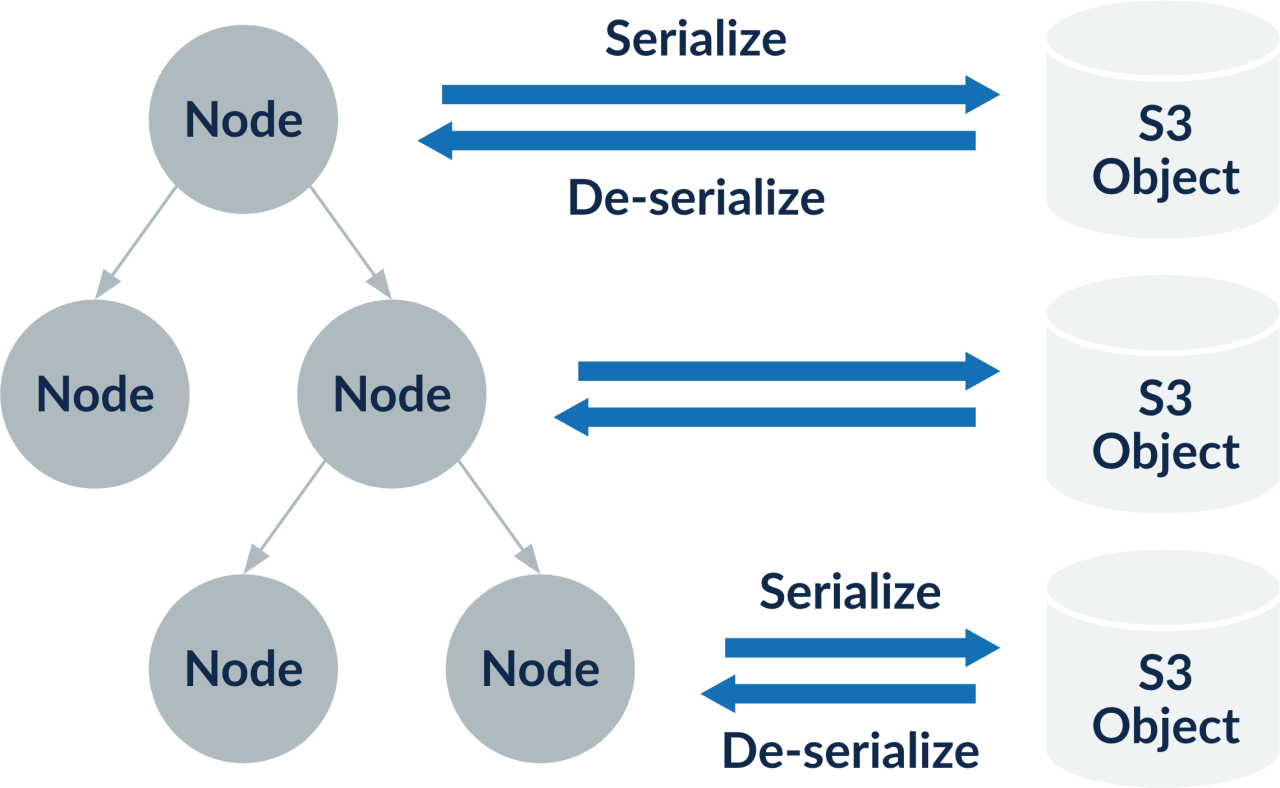
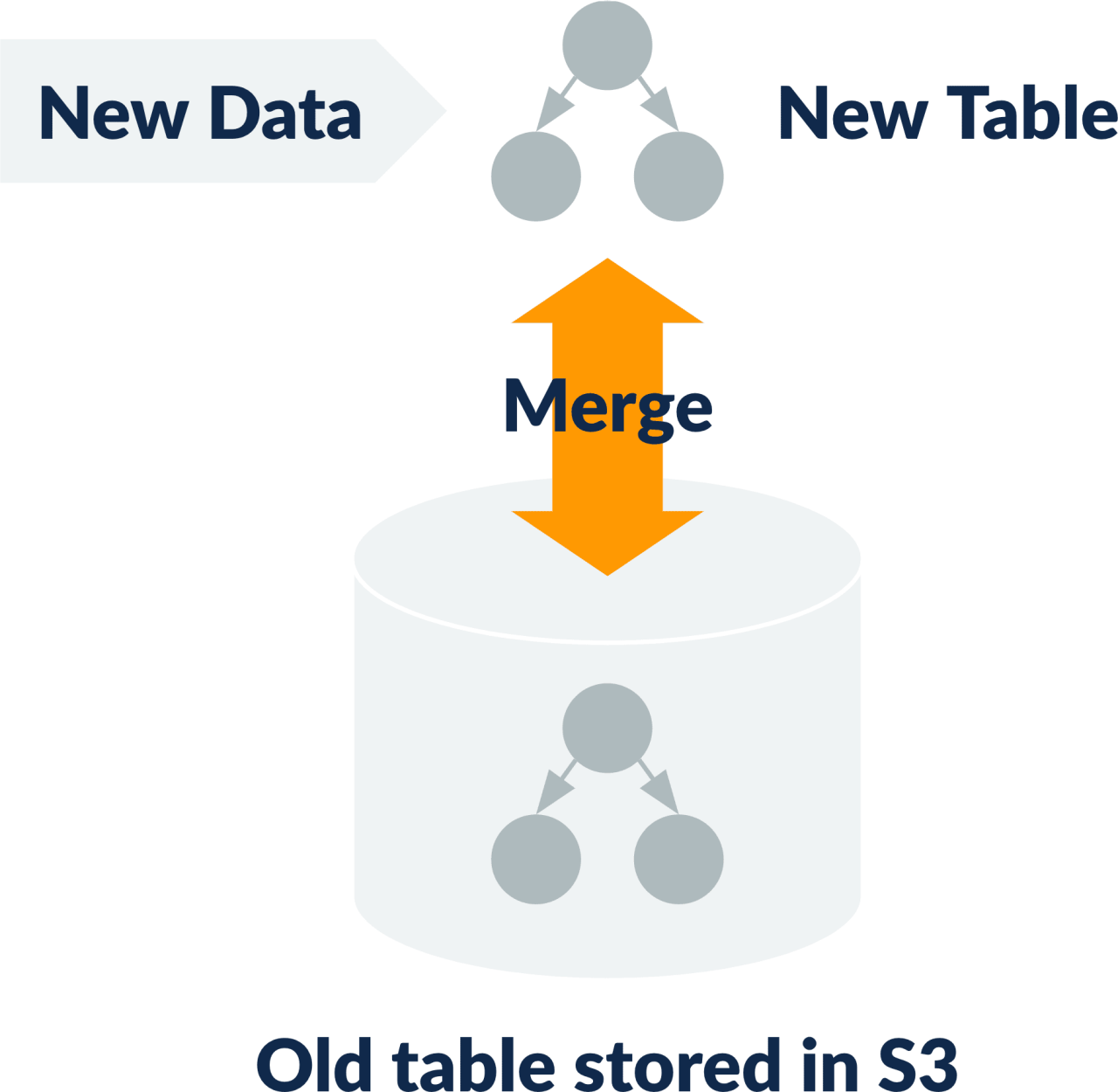
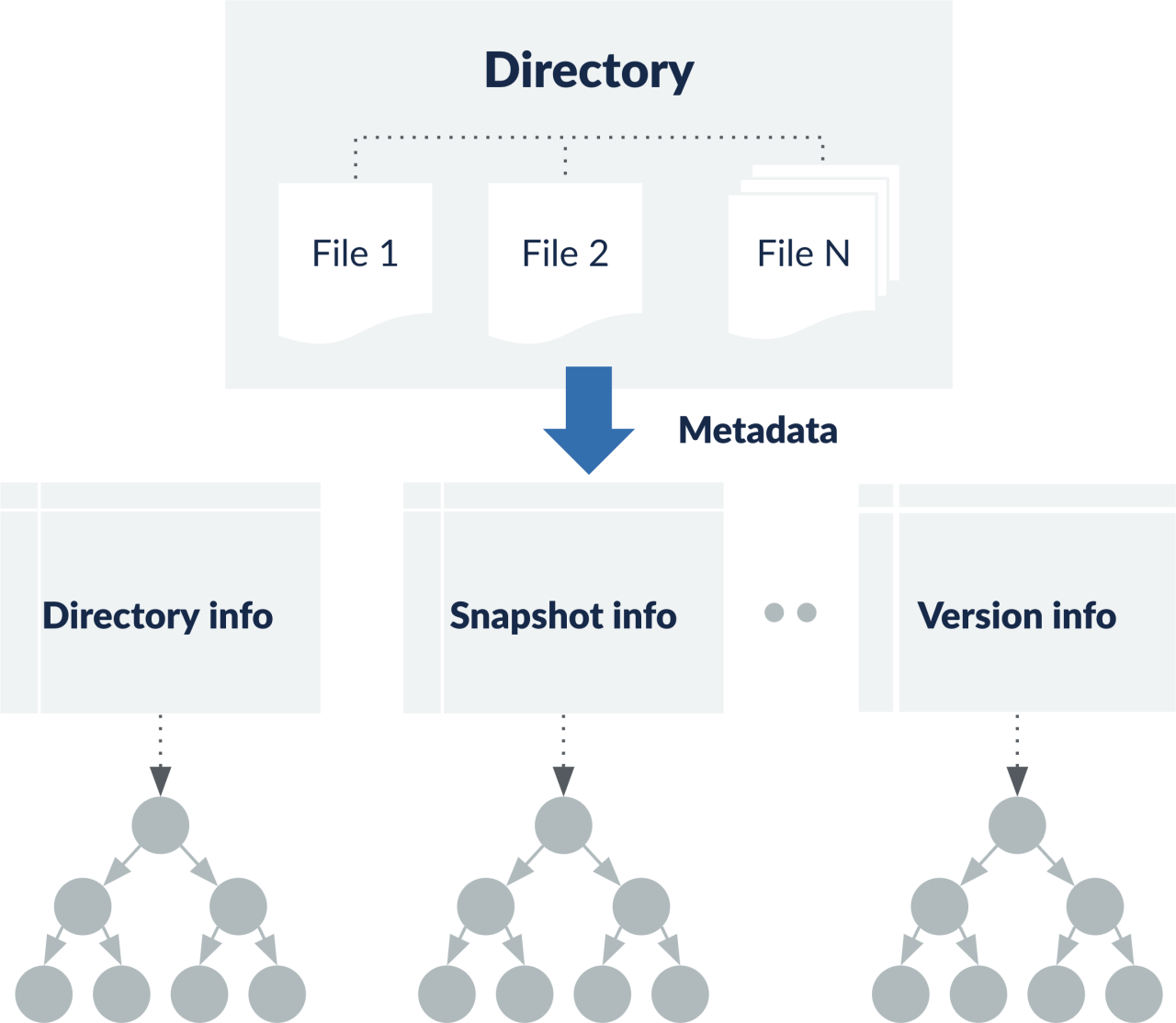
The most important component of a database is its index — which is used to search data. This is maintained in sorted order for quick retrieval of information. If this index becomes huge, it starts to cause slower operations. Once written to S3, frequent updating and re-writing of the index can get expensive, as IOs on S3 are costlier. Therefore, it is better to create a new index for bulk data before merging with the existing index.