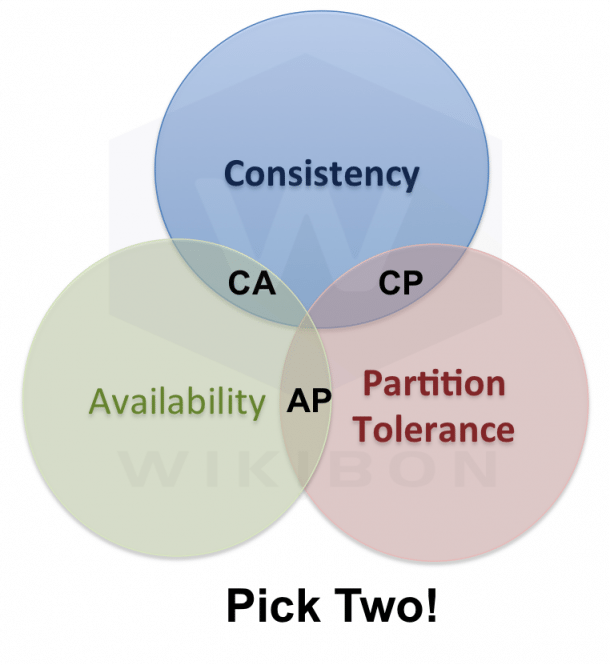
The CAP Theorem: Image used by permission © Wikibon
Even so, I was unfamiliar with the CAP theorem mentioned in the blog post, which I found very interesting. Databases need to be consistent, available, and have partition tolerance. Consistency ensures that the data we thought we put in there is the data that is still in there. Availability speaks to the database being available for use at any particular time, and partition tolerance speaks to scalability. The idea of the CAP theorem is that any given database can be only two of these things at once. It can be consistent and available (the CA model), consistent and partition tolerant (CP model), or available and partition tolerant (AP model) –– but no database can be C, A, and P all at the same time. For example, if you spread a database across the world and make sure it’s available all the time, the only way you can do that is through an eventually consistent model – which is how databases like Cassandra work.
Oracle operates on a CA model, which means it doesn’t scale as well, but it’s data will always be consistent and mostly available. Spanner uses the CP model, which means it’s scalable and consistent, but might not be as available as Oracle. This is an important difference when considering how its used.
Deterministic vs. Probabilistic
David then went on to explain the difference between deterministic and probabilistic workloads. The former describes an outcome that must be the same every time, such as adding up payroll or billing. Given the same inputs, a deterministic result should always be the same, regardless of which application computes it. Probabilistic outcomes are used when a “good enough” number is, well, good enough. A perfect example would be to predict the price a given ad might fetch in an on-demand marketplace. It’s OK to be off a few cents; what matters is how fast you compute the result.
Oracle is best for deterministic workloads, but Spanner was designed for probabilistic workloads. David estimated that 5% (by license revenue) of Oracle workloads were probabilistic and would be alright with Spanner’s lower availability numbers.
Caution
The folks at Wikibon still expressed caution. Spanner is available as a product, but has very little infrastructure support. For one thing, no one knows how to back it up! (Now we’re in my neighborhood.) All the same, they do recommend getting an Oracle Spanner mug, and placing it on your desk whenever talking to an Oracle Sales Rep.