If 2026 has taught infrastructure teams anything, it’s this: cyber resilience strategy cannot rely on the extremely fragile supply chain that is severely affecting servers, memory, and appliances.
Right now, the “normal” rules of infrastructure planning are breaking down: server component lead times are stretching past ~40 weeks, refresh cycles are slipping, and even getting a pricing quote can feel like buying on a spot market—24-hour validity windows and constant repricing.
And that volatility doesn’t just hit compute projects. It hits the systems you depend on for last-resort recovery. Amid growing hardware shortages and volatility, cloud-based backup and recovery solutions are rapidly displacing costly on‑premises systems.
In this blog, we’ll take a closer look at the hardware headaches driving this migration. Continue reading to learn more, and check out Druva’s new white paper, which explores verified G2 findings about why buyers are leaving legacy behind. Plus, those looking to break from hardware headaches can switch to Druva and score up to 6 months of FREE coverage! Zero hardware means zero stress; make the switch today.
The new risk no one budgeted for: “procurement-gated resilience.”
Most organizations think of cyber resilience risk as ransomware, insider threats, misconfigurations, and recovery complexity.
But 2026 added a new category for organizations that take a stand-up-your-own infrastructure-and-appliance approach: procurement risk.
What is the impact on your Cyber Resilience plan if procurement is at risk for the traditional backup vendor? How does a strained procurement process with a traditional backup provider affect your overall Cyber Resilience strategy?
When resilience depends on hardware-dependent architectures (backup servers, proxies, scale-out nodes, or appliance expansions), a shortage turns into a business problem fast—because you can’t “wait out” an incident.
Here’s what buyers are seeing in-market:
- 40+ week lead times for server components, effectively suspending normal refresh cycles.
- Spot-market buying behavior: short quote windows, frequent repricing, and re-quoting mid-project.
- Appliance and OEM exposure: vendors and partners whose bill of materials is tightly coupled to scarce components get disproportionately impacted.
What’s driving it: the AI supply squeeze (and why it’s not “temporary”)
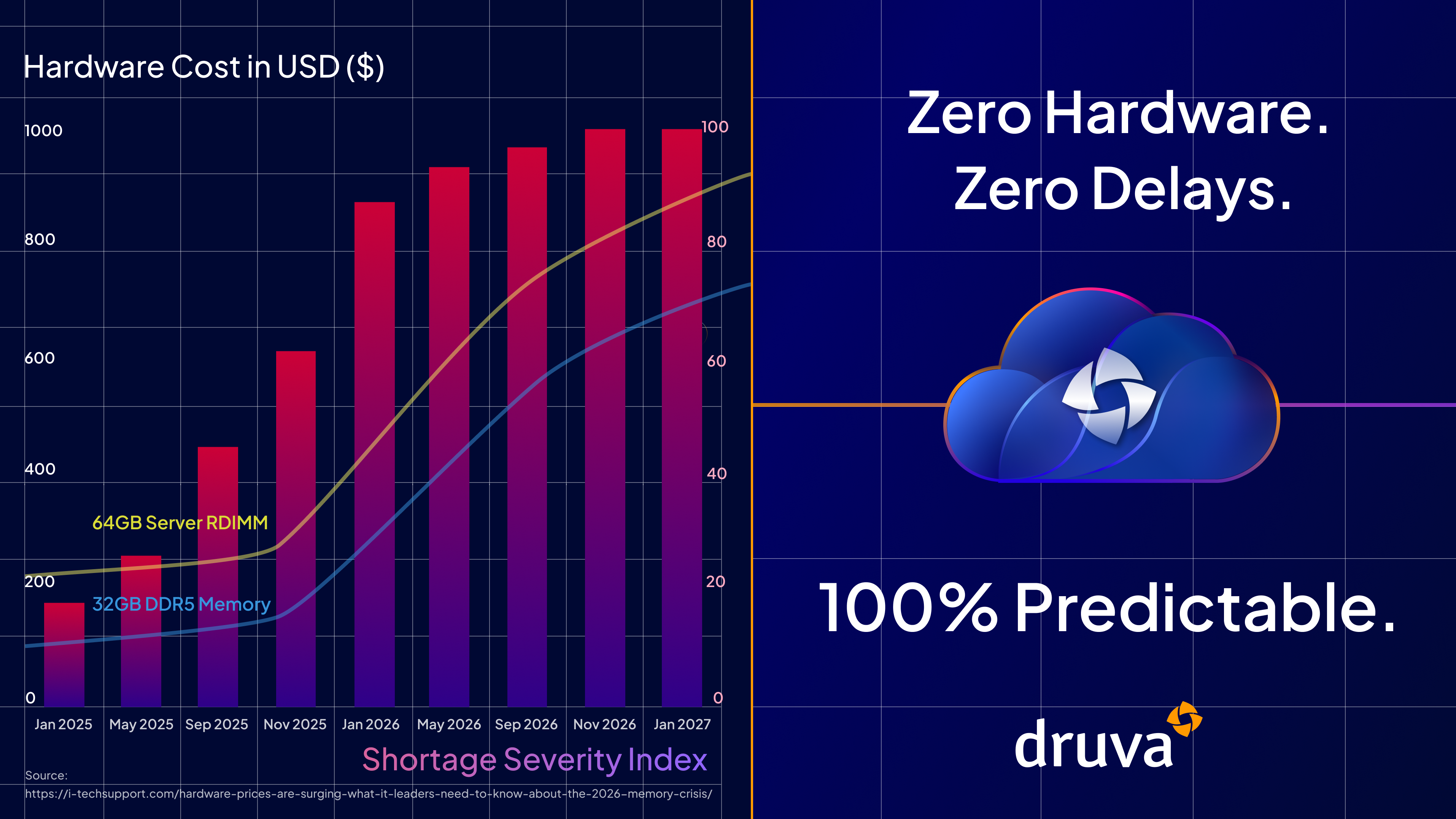
This isn’t just a logistics blip. The market signals point to a structural crunch driven by the AI infrastructure boom, which is absorbing high-margin memory supply (HBM and server-class DDR5), while conventional enterprise DRAM availability tightens.
And when memory gets volatile, the ripple effects show up everywhere: server configurations, appliance builds, OEM allocation behavior, and total project costs.
Concrete examples cited in-market include steep jumps in DDR5 pricing in 2026 relative to 2025 (e.g., 32GB DDR5 kits spiking from roughly $100 to $350+), and increases in server memory prices (e.g., 64GB RDIMMs rising from roughly $255 to $450 within a short window).
The hidden tax on traditional backup: waiting
In a hardware-volatility cycle, “traditional” backup and recovery approaches tend to accumulate invisible costs:
- Delay costs: projects slip while teams wait for nodes, components, or expansion hardware.
- Budget shock: re-quotes, change orders, expedited shipping, and “surprise” BOM inflation.
- Resilience ceilings: recovery readiness constrained by appliance capacity limits during demand spikes or refresh freezes.
This is why we’re framing 2026 as an infrastructure moment—not just a backup moment.
Because when the infrastructure market goes volatile, resilience architectures that depend on hardware inherit that volatility.
The 2026 hardware crunch is making resilience unpredictable. Here’s how to go Zero.