Much of the massive amount of data today is generated by automated systems, and harnessing this information to create value is central to modern technology and business strategies. Machine learning has emerged as a valuable method for many applications—image recognition, natural language processing, robotic control, and much more.
Download White Paper: Public Cloud Backup Delivers More for Less
By applying machine learning to system-generated debugging logs, we’ve gained key insights and transformed these logs into critically valuable data sources.
Existing Monitoring: Manual Thresholds
Most software products generate logs that are used for root-cause analysis and troubleshooting. Though these logs offer useful insights into real-time performance, mining them for actionable knowledge is challenging. The data they contain lacks structure, and often, they simply don’t contain enough analytical information.
Software as a service (SaaS) solutions present even more difficulties. Cloud operations teams must monitor the logs in real time, in addition to the numerous other data streams under their watch.
Typically, monitoring teams are tasked with:
- Identifying and alerting if any part of the service is not operating as expected.
- Looking for signals that indicate imminent cascading failures.
- Understanding how normal cycles of operations shift during upgrades, patches, and hotfixes.
Traditionally, teams and developers monitoring cloud operations depend on their past experiences with the systems, as well as certain manually defined rules, to detect anomalous behavior. However, rule-based monitoring is convoluted and isn’t scalable. The complexities of modern systems with multiple components in a dynamic business environment make it difficult for a single team to see and understand all of the patterns. In addition, these static, manual rules often fail to catch anomalies, creating false negatives—or even worse, they trigger alerts about anomalies when there are none, creating false positives.
At Druva, we wanted to develop an efficient way to detect anomalies as quickly as possible. Rather than relying on product knowledge and manually set thresholds to detect anomalous behavior, our goal was to leverage technologies that learn the complex patterns, account for seasonality, and perform with better precision than manual systems.
Deeper Look At Anomalies
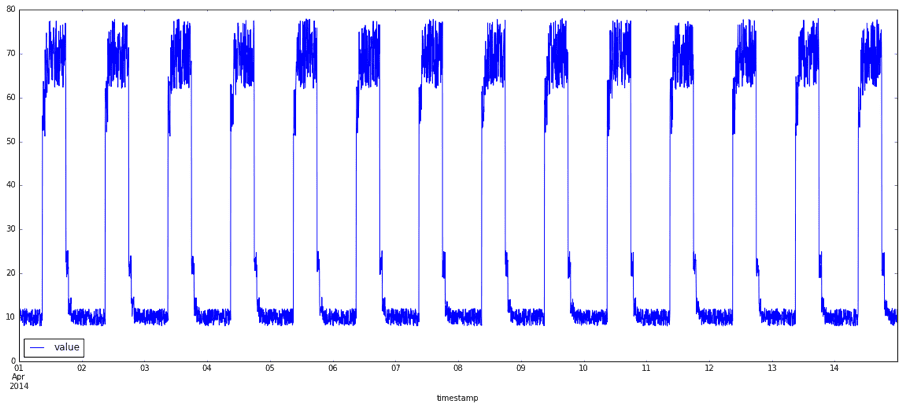
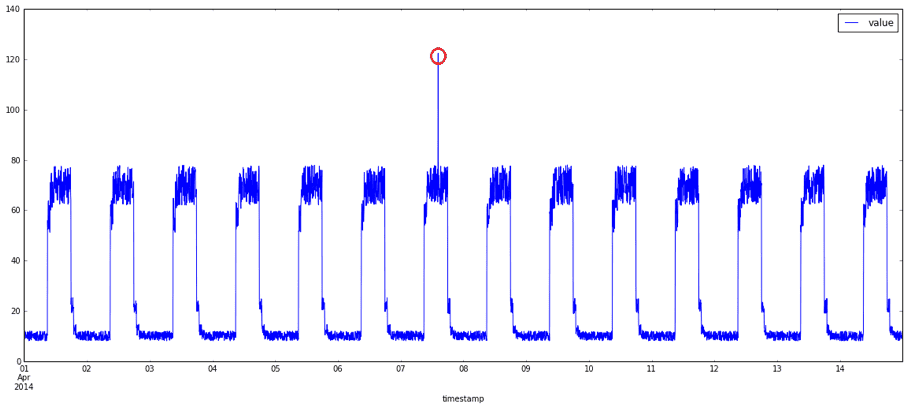
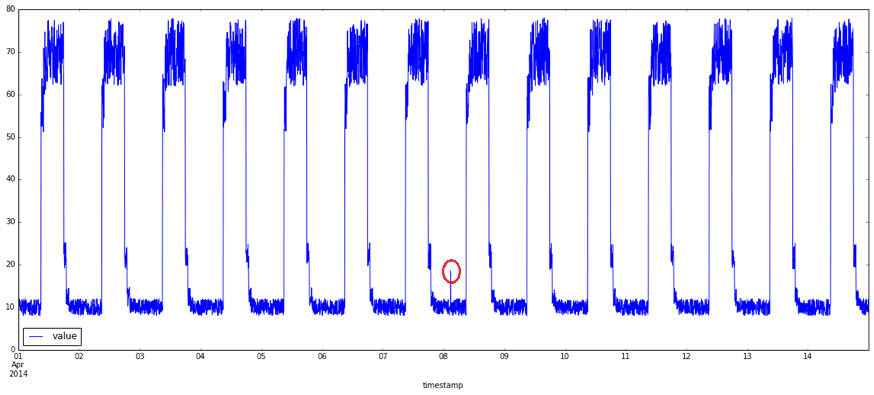
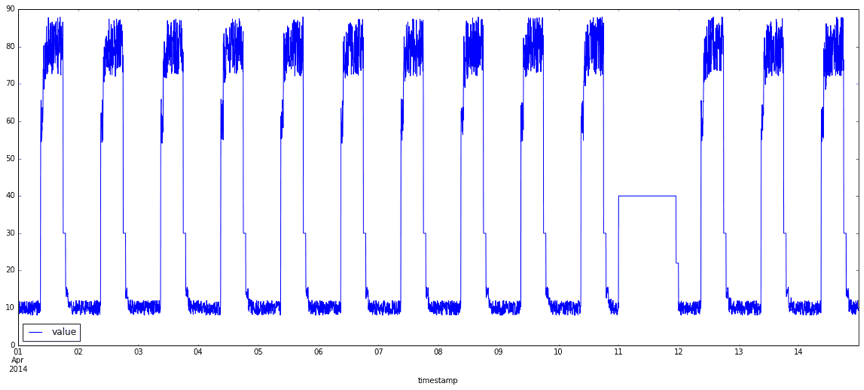
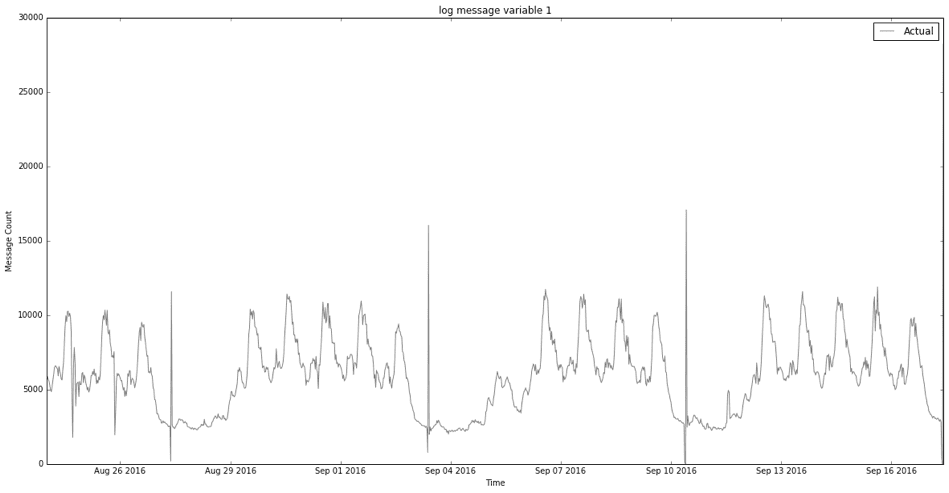
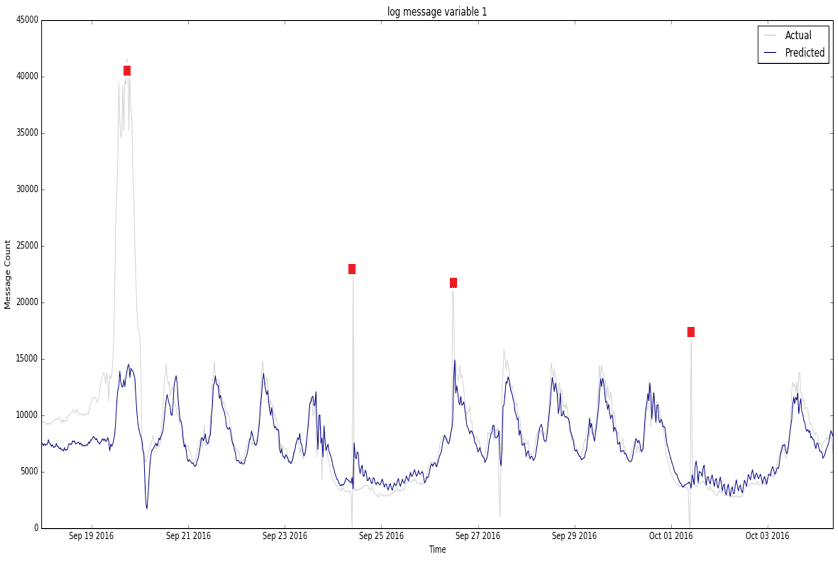
What exactly are anomalies? Simply put, an anomaly is any deviation from standard behavior. In the world of software, there are three main types of anomalies, which are depicted in the following graphs.
Figure 1 shows a normal data representation.