Phase 1: AI-Driven Analysis & Specification Generation
Our initial challenge wasn't a matter of code, but of deep comprehension. Migrating over 300 APIs with absolute fidelity meant leaving no room for ambiguity. A simple, direct translation would have merely propagated inherent defects and structural weaknesses. Instead, we had to meticulously reverse-engineer the true intent of every endpoint, and crucially, achieve this feat at a scale far beyond manual scrutiny.
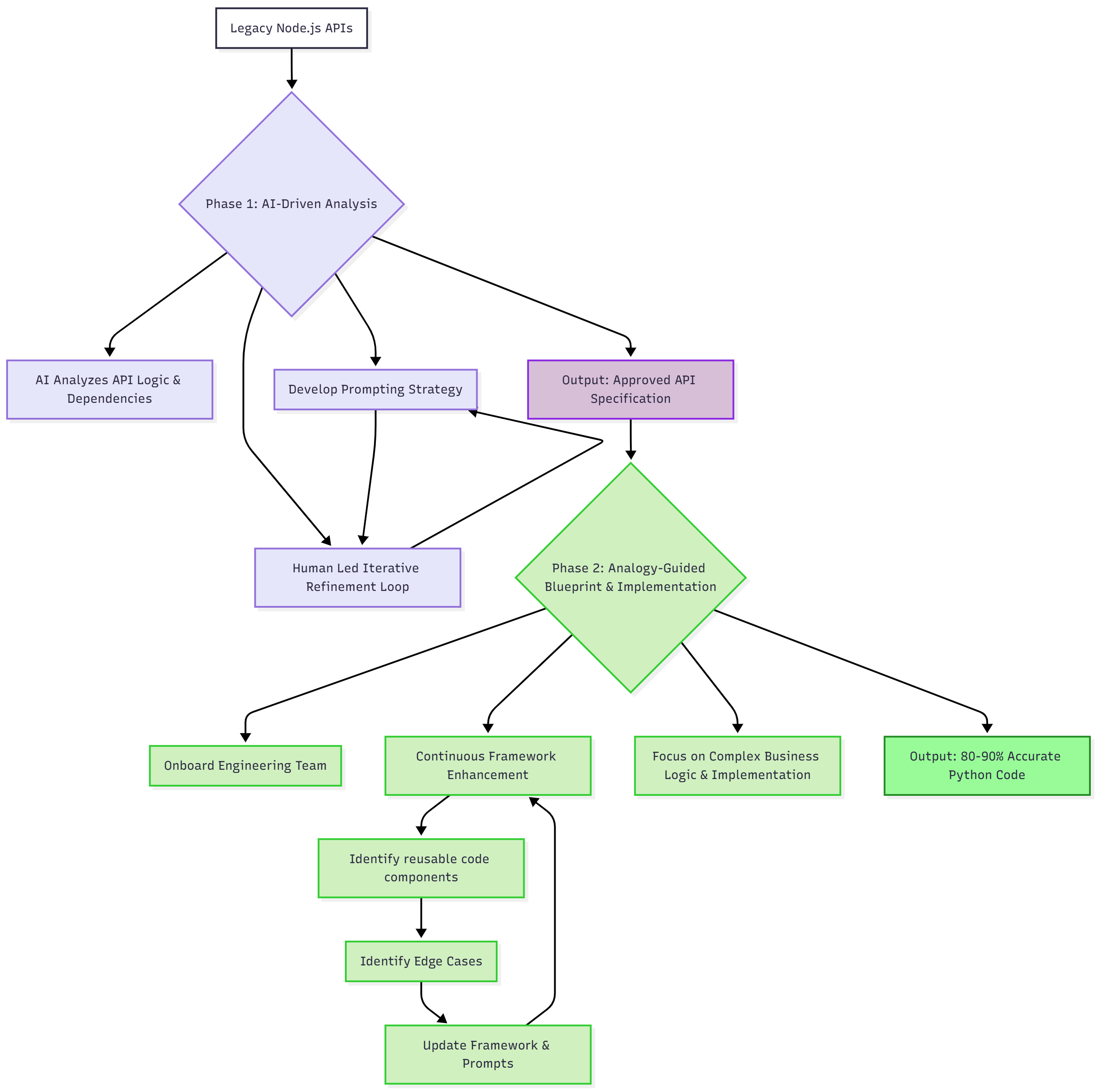
To solve this, we built a rigorous, AI-assisted analysis pipeline. We didn't just ask an AI to "read the code." We engineered a process that treated the AI as a junior engineer, tasked with deconstructing each Node.js API and documenting its findings in a highly structured format.
We fed the AI the source code for a single endpoint, along with a strict template to follow. This templated approach was the key to making the process generic and scalable. It ensured that whether the API was a simple GET request or a complex multi-step POST, the output would be consistent and predictable.
The result for each API was a comprehensive analysis.md file, our definitive source of truth. This wasn't just documentation; it was a contract that captured every critical detail:
The API's Core Function: A clear description of its purpose, the business logic it encapsulated, and its role in the wider system.
The Data Contract: A precise definition of the request and response schemas, including field names, data types, validation rules, and example payloads. This was crucial for maintaining 100% response compatibility.
Database Interactions: A full trace of its data footprint, detailing the tables it touched, the queries it ran, and any transactional boundaries.
Error Handling: A complete catalogue of potential error states, including the exact messages and HTTP status codes the original API would return.
But the AI's output was never blindly trusted. To ensure consistency and accuracy, we implemented a series of human-led quality gates. Before any analysis.md file was approved for implementation, it underwent a meticulous peer review. Our engineers would validate the AI's findings against the original Node.js code, checking for:
Fidelity: Did the response schema exactly match the live Node.js endpoint?
Completeness: Were all business rules, edge cases, and error conditions identified?
Security: Were authentication and authorization requirements correctly captured?
This human-in-the-loop approach combined the speed of AI-driven analysis with the rigor of senior engineering oversight. It allowed us to create a complete, trustworthy blueprint for all 300+ APIs, turning a mountain of ambiguous legacy code into a clear, actionable migration plan. This foundational work enabled us to move into the implementation phase with speed and confidence.
Phase 2: The Analogy-Guided Blueprint Framework
With high-quality specifications in hand, our challenge shifted from what to build to how to build it with consistency and quality at scale. Simply letting engineers or an AI loose on the specifications would have inevitably led to architectural drift, with different developers solving similar problems in slightly different ways. This would create a maintenance nightmare down the road.
To prevent this, we developed the Analogy-Guided Blueprint Framework. This was our structured approach to implementation, ensuring that every new Python API was functionally correct but also architecturally aligned with our existing codebase. The core philosophy was a two-part strategy: use an existing API as a high-level structural guide, but build the actual logic from the ground up based on a deep analysis of reusable components.
The "Analogy": Finding the Structural Where
For each new API, the process began by finding a well-written, existing Python API in our codebase that served a similar architectural purpose. For example, an API that kicked off a background job would be compared to an existing API that did the same. This analogy was never used for code-cloning. Instead, it provided a high-level map, answering questions like:
What files need to be created (handler, service, schema, etc.)?
What decorators are needed for authentication and validation?
How should the core logic be separated between the service and data layers?
This gave us a consistent skeleton for every new API, ensuring they all fit neatly into our established architecture.
The "Blueprint": A Bottom-Up Plan for the How
With the structure defined, we performed a deep, bottom-up analysis to find specific, reusable code. This is where we faced our first major challenge: avoiding the "smart copy-paste" trap. Early on, we found that the AI, if not properly guided, would try to copy too much from the analogy, including irrelevant business logic.
We overcame this by making our analysis strictly table-driven. Instead of searching for vague business terms, we identified the core database tables an API would interact with and then performed a targeted search for those table names in our data layer. This instantly revealed every existing, battle-tested function that already operated on that data. This simple but powerful technique dramatically increased code reuse and prevented the proliferation of redundant database queries.
The output of this analysis was a detailed implementation.md blueprint. This document was the final contract for the AI, a precise, step-by-step plan that included:
A list of files to be created or modified.
The exact signatures of existing functions to be reused.
The required logic for any new functions.
A validation checklist that tied every implementation detail back to its original requirement in the analysis.md file.
This blueprint became our primary tool for overcoming our second major challenge: preventing architectural drift at scale. By requiring every implementation to start from a blueprint, we ensured that every developer—and the AI—was building to the same high standard. The final step was a bottom-up implementation, starting from the data layer and moving up to the API layer, ensuring a clean, layered, and maintainable final product for every single API.
A Multi-Layered Approach to Quality Assurance
Our commitment to a seamless transition demanded a testing strategy that could guarantee perfect functional parity between the new Python services and their Node.js counterpart. We were not just migrating APIs; we were building the entire quality assurance safety net from the ground up. It wasn't enough to test our Python code in a vacuum; we had to prove that it behaved identically to its Node.js predecessor under all conditions.
To achieve this, our QA team designed a multi-layered approach that combined automated developer-level testing with a powerful, centralized parity-testing framework.
Developer-Level Testing: AI-Generated Scaffolding
Our commitment to quality was built-in from the start. Our AI-driven framework not only generated production code but also created skeleton unit and integration tests for every API. This scaffolding included boilerplate for mocking dependencies and asserting the "happy-path" case, derived directly from examples in the analysis.md file. This approach provided developers with a clear foundation for comprehensive testing, ensuring that every new API had baseline test coverage from its inception.
QA-Driven Parity Testing: Validating Against the Source of Truth
The cornerstone of our quality assurance strategy was an automated parity-testing framework built by our QA team. This framework was designed to act as an impartial referee between the old and new systems. For any given API, the process was simple but effective:
A Single Source of Truth: The QA team used the analysis.md file for each API as the definitive guide for writing test cases. This ensured that every piece of business logic, every validation rule, and every error condition that was identified during the analysis phase was explicitly tested.
Parallel Execution: The automation framework would take a single request and send it to both the legacy Node.js endpoint and our new Python endpoint simultaneously.
Deep Response Comparison: The framework would then perform a deep comparison of the two responses, validating not just the status code, but every field in the payload and every header. Any discrepancy, no matter how small, was flagged as a failure.
This automated, side-by-side comparison was our ultimate safety net. It provided indisputable proof of response compatibility and allowed us to deploy new APIs with a high degree of confidence, knowing that they were a perfect functional match for the services they were replacing.
Quantified Impact: Delivering 3x Faster Than Projected
Metric
| Traditional Estimate
| AI-Driven Outcome
|
Project Duration
| ~5 Quarters
| 1.5 Quarters
|
AI Code Generation
| NA
| 80–90% correct on first iteration
|
Test Coverage
| Manual
| ~95% Auto-generated
|
Conclusion: A Blueprint for the Future
This project was more than a technical migration; it was a fundamental shift in how we approach engineering challenges. The speed and quality we achieved were not the result of a single tool, but of a new mindset built on a few core principles.
Learn by Doing, Not by Reading: Adopting AI was initially daunting but direct, expectations-free experimentation delivered exponential learning.
Tools, Not Threats: Treating AI as a creative teammate unlocked not only code velocity and consolidation, but a faster path to best practices discovery.
Iterative Feedback is Everything: Our biggest successes—and biggest time-savers—were from rapid, candid “tight loop” feedback and willingness to keep tuning.
Share to Scale: Documentation and knowledge-sharing for our framework meant our success became organizational, not just local.
What began as a race against the clock to migrate a legacy system has become a new template for modernization at Druva. This project compressed a five-quarter timeline into just 1.5 quarters, but its true impact lies in the capabilities we built along the way.
Our AI-development framework components, and the skills our team developed, are now being reused to accelerate new feature development, streamline developer onboarding, and inform future architectural projects. This experience proved that a bold, learn-fast strategy is essential when faced with ambitious goals.
By thoughtfully integrating AI not just as a tool, but as a catalyst for systems thinking, we unlocked the speed and confidence to build deeper customer trust by delivering reliable, cutting-edge solutions at the pace modern business demands.
Learn more about how Druva pioneers new approaches in engineering. Read more on our tech blog.
Ready to modernize your data security? Discover Druva’s powerful SaaS-first Data Security Platform today!