In 2020, Druva acquired SFApex, a specialized Salesforce backup and seeding solution serving a substantial customer base. While SFApex had built an innovative product; integrating this technology into Druva's enterprise-scale platform presented fascinating engineering challenges.
This is the story of how we transformed a distributed monolith architecture into a scalable, secure data protection platform—all while maintaining zero downtime for existing customers. It's a tale of technical debt, architectural evolution, and infrastructure reliability.
The Starting Point: Understanding SFApex's Architecture
When we first assessed SFApex's technical landscape, we found a system that embodied both the agility of a startup and the complexity that comes with rapid growth:
The Good:
Proven Market Fit: An established customer base successfully backing up critical Salesforce data and seeding data across Salesforce orgs.
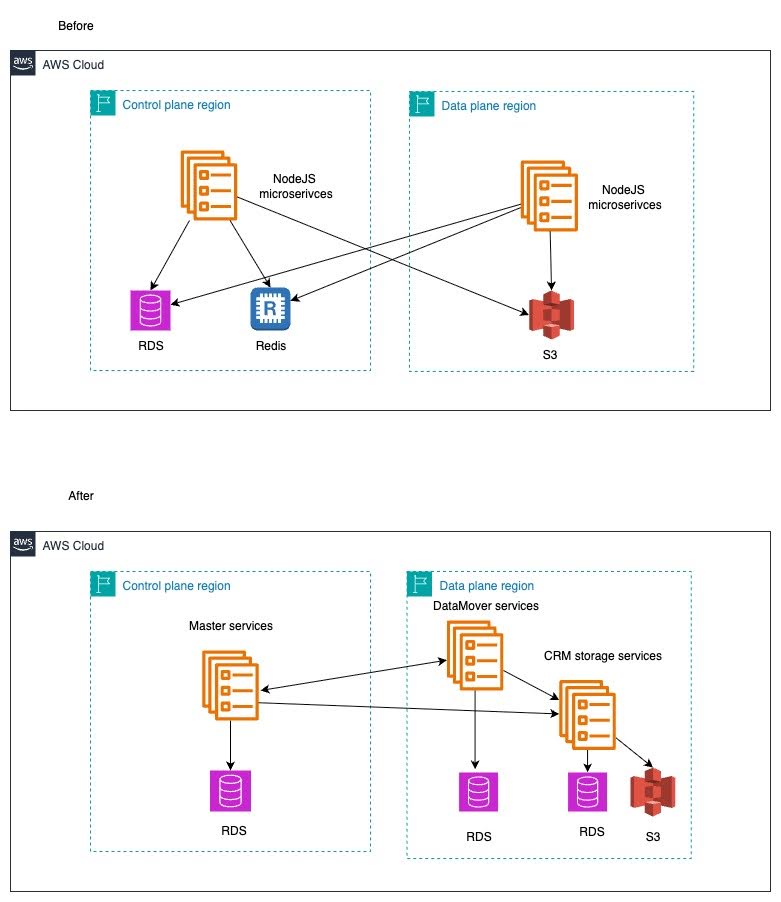
Flexible Infrastructure: Node.js microservices deployed on Heroku with rapid deployment capabilities.
The Challenges:
Distributed Monolith with Shared State: Multiple microservices sharing a single PostgreSQL database, creating tight coupling despite the distributed architecture.
Communication Complexity: Heavy reliance on Redis for inter-service synchronization.
Lack of Dynamic Scaling: Fixed number of service instances resulted in high costs and inability to handle burst load.
Security Compliance Gaps: Architecture didn't meet Druva's enterprise security standards.
Limited Observability: Minimal monitoring and debugging capabilities across distributed services.
The Vision: Druva-Scale Architecture
To integrate SFApex into Druva's Data Security Cloud, we needed to fundamentally reimagine the architecture while preserving the core value proposition. Our target architecture embraced Druva's proven patterns:
Service-Oriented Architecture (SOA): Moving from microservices with shared databases to truly independent services with separate RDS and clear boundaries.
Architectural Layering:
Control Plane: Configuration management, job scheduling, and orchestration
Data Mover: Regional services for long-running jobs like backup, restore, and download
CRM Storage Service: Regional CRM specialized storage service for S3 interactions
Enterprise Security: Enhanced encryption through AWS KMS, compliance with SOC2 and other enterprise requirements.
Challenge : Zero-Downtime Migration Strategy
The most critical constraint was maintaining service continuity and data consistency. Some customers ran high-frequency backups every 15 minutes, meaning any disruption could create data protection gaps - completely unacceptable for a data security company.
Our approach involved a parallel migration strategy designed around four key phases:
Phase 1: Shadow Architecture Development
After analyzing the SFApex architecture, we made several strategic decisions:
Language Migration: Rewrote the entire codebase from Node.js to Python which was suitable for dynamic data response from Salesforce.
Architecture Overhaul: Implemented service-oriented architecture (SOA) proven for other Druva workloads.
Performance Benefits: Eliminated Redis synchronization bottlenecks and improved scalability using service specific databases and stateless services having dynamic scaling support.
Storage Compatibility: Maintained the same storage layout to minimize migration impact
Phase 2: Data Migration to Druva S3 Buckets
Following Druva security standards, we implemented secure data migration from original S3 buckets to Druva-managed S3 buckets. Before migrating any customer to the shadow architecture, our data migration service securely copied their historical backup data to Druva S3 buckets, ensuring complete data continuity and enhanced security compliance.
Phase 3: Gradual Customer Migration by Functionality
Instead of a big-bang migration, we moved customers in carefully planned waves for each major operation: backup, restore, discovery, and other core functions.
Migration Sequence:
Internal Customers: Started with Druva's own Salesforce org and internal demo customers
Low-Risk Customers: Smaller customers with less backup data
Standard Customers: Average size customers with daily backup schedules
High-Risk Customers: Customers with large data volumes
Once migrated, customer configurations were updated to automatically route subsequent jobs to the new architecture.
Phase 4: Monitoring and Rollback Capabilities
All operations after migration were closely monitored for data consistency and infrastructure issues. We maintained the ability to instantly revert to the original system in case of any issues with the new architecture.
Critical Success Factors:
Automated Consistency Checks: Ensured source and destination data remained identical after backup migration
Customer-Specific Rollback Plans: Rollback facility available for each customer and operation combination
24/7 Engineering Coverage: Engineers on-call during all migration windows
Transparent Communication: Customers informed about migration in advance as data was copied to Druva S3 buckets
Lessons Learned:
1. Parallel Systems Enable Confident Migration
Building shadow infrastructure allowed us to test everything before customer impact. The ability to rollback any customer within minutes was crucial for team confidence and customer trust.
2. Gradual Migration Beats Big Bang Every Time
Customer-by-customer migration in phases allowed us to:
Learn from each migration
Adjust our process based on real feedback
Minimize blast radius of any issues
Build confidence progressively
3. Test Your Rollback Plan
We extensively tested customer rollback procedures. When we encountered one customer issue during migration, we reverted them to the old system in under 10 minutes—that preparation was invaluable.
4. Language and Architecture Decisions Matter
Choosing Python and SOA wasn't just about technology—it was about leveraging existing team expertise and proven patterns to reduce risk and accelerate development.