By virtue of their inherent mobility, mobile devices are more likely than attached storage devices to backup their data over a network; and today’s devices have multiple options: office Wi-Fi, a hotspot at the local coffee store, even a telco data plan. Although backup software can be configured to use a specific method, waiting for your chosen network to become available exposes you to significant risk. Imagine if your VP were to lose his or her laptop in an airport terminal, moments after putting the final touches to your latest sales presentation! It should be obvious that when devising a backup strategy, you need to weigh the cost of Wi-Fi access or data plan overages against the very real possibility of losing your critical data forever.
One of the keys to ensure the data is protected is to use an efficient algorithm that not only compresses but also removes data redundancies so the minimal amount of data is transferred for the maximum amount of data protection. To accomplish this, vendors utilize deduplication, but not all deduplication is the same. Understanding their differences can aid in ensuring your organization meets its data protection objectives.
So, what are the various types of deduplication?
Deduplication at Target: Inefficient for Network but Efficient on Storage Savings
With deduplication at target, you copy your data to a storage device, the storage processor identifies the duplicate data, and maintains only a single copy—all other copies are discarded. Now, whenever you need to access the relevant data you get it from this single copy.
Deduplication at target can be performed in either inline or offline mode. In the case of inline deduplication, as new data is being received by the storage processor, a ‘fingerprint’ of the data is compared with existing fingerprints in real time. If the same data already exists on the target, it is skipped and only a reference to the existing data is maintained. In offline mode, data is first copied to a target; an offline scan then removes duplicated data and maintains a single copy. All references to the data then point to this single copy.
Consider a situation where you have multiple copies of a file, each slightly different from one another (e.g., a work that is in progress). Using deduplication at target, each device will copy its version of the file over a network layer to the backup store. Whether in online or offline mode, the storage processor in the backup store will then scan these files, find the unique content in each and delete all but one of these unique parts, maintaining a single copy of all the data. However, this creates significant overhead as each device’s version of the file must initially be sent over the network. It is highly inefficient in terms of bandwidth but conducive to overall storage savings, as only a single copy per target is maintained.
What if you could identify whether the data has already been stored at the target before copying, and skip sending it altogether with just a pointer to the stored copy? This is called deduplication at source.
Local Deduplication at Source: Saving Network Bandwidth at the Cost of Endpoint Resources
In the case of local deduplication at source, data is scanned locally first, followed by the identification of any unique data, which is then backed up once. Subsequent backups need only include a reference to the original data, thus conserving bandwidth. While there is the advantage to only sending unique data across the network once, scanning for and comparing this information locally can be resource-intensive and weigh down heavily on the CPU and memory of a mobile device. For very large datasets, this can be highly inefficient for an endpoint device.
Further, this only ensures that deduplication happens across just a single device at a time.
Now, this is alright for your personal laptop, but for business organizations with multiple copies of data spread across multiple devices, duplicate data across these devices gets transferred multiple times.
Global Deduplication at Source: The Best of Both Worlds
The answer to the dilemma is global deduplication at source. Using this method, the data ‘fingerprint’ is calculated at the source; this fingerprint is then sent across to the target where it is compared to existing data. If a match exists, regardless of its source, only a reference to the data will be copied. By ‘global, we mean across all users and their devices. The two earlier methods are either user or device only and therefore never get the network-effect that global delvers, which significantly lowers the overhead of data being transferred.
Take this scenario for example: a file is sent as an email attachment to a group of coworkers. With the deduplication at target method, each mobile device will copy the file over a network layer to the target, where all but one of these files is deleted and a single copy maintained. Using the local deduplication at source method, once a file is sent to the backup store, no other copies will be sent by that device and only the metadata of the file with a unique identifier will be transferred, but multiple devices will send that file each time as it’s unque within that device. In the case of Global deduplication at source, a file is sent across network only once, be it for 10 devices or 100s.
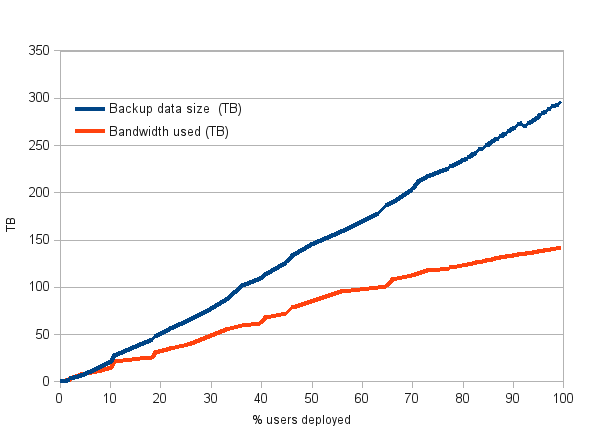
As the number of users deployed increases, the duplicate data begins to accumulate. For successive users, only a fraction of their entire backup set data will need to be uploaded. This reduces bandwidth usage and improves the speed of deployment as it is rolled out across the organization.
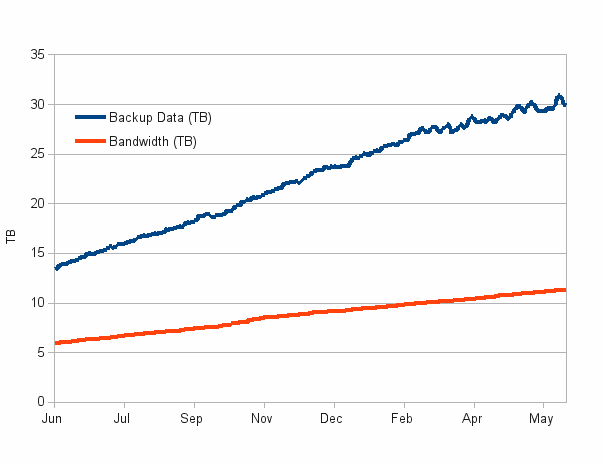
In the real-world example below, a very large deployment in a global consulting company was implemented within a single business quarter thanks to global deduplication at source. While the users had nearly 300 TB of total backup data, less than 150 TB of data was ultimately transferred to the backup cloud. This was made possible by deduplicating not only on a per-user basis, but globally across the entire organization. This 50% data transfer savings applies to the initial deployment, and it increases to 80% over time as you only backup unique data.