Overview
When processes written in Go Lang work with unstructured data, they tend to consume a lot more memory than expected. This blog gives insight into how we at Druva overcame this problem and leverage Go Lang in a memory-intensive application.
Background
Our backup process is written in Go. This is a typical use case where the process requires frequent Go Lang memory management allocation. It reads hundreds of files in parallel, does some processing like compression of data, and sends that over the network. The backup process works on GBs of data per minute. To read these files, it allocates and processes buffers. However, previous buffers that are no longer in use are not freed (or at least that’s what it looked like at the start). The end result is a backup process that consumes huge amounts of memory.
How did we identify the root cause of the issue?
At first, it looked like a memory leak issue. We scanned our code multiple times to see if we were releasing any object references. With Go being a garbage-collected language, that possibility was very minimal. We tried forcing frequent GC by setting different config values — it did not help.
We used pprof to do memory profiling and to find out where maximum memory allocation happens. As expected, it was happening at a place where we were allocating buffers before reading data into the buffer. But then we noticed a surprising result in our memory profiling. We took memory profiles at frequent intervals and specifically at a time when we were seeing high memory usage. The profile showed huge allocated memory but very low in-use memory. What does this mean? This means GC has released the memory. If it was not released by GC, it would have been captured in the in-use memory profile. The top command on Linux also was showing the same information, very low RSS (resident set size) memory but high VSZ (virtual memory) usage.
What was happening here? Because we were allocating a buffer of differing sizes — from 1 byte to 16MB — Go's memory scavenger was not handling those requests efficiently. It was allocating more new pages and was not reusing already allocated and unused pages. This was a result of fragmentation due to random buffer size.
How did we solve the problem?
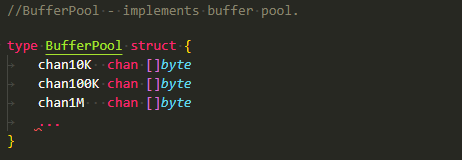
We used a BufferPool to solve the memory fragmentation. Allocate a fixed-size buffer. Even if the request is for 1b, allocate a 1kb buffer. We kept four different sizes for the buffer: 1K, 100K, 1M, and 16M. This is a typical use case for our process for these sizes.
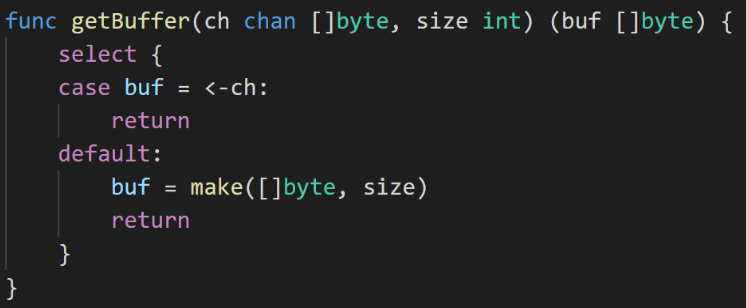
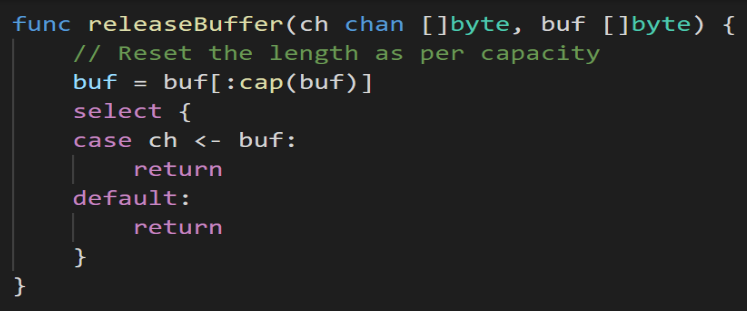
What the process does is get a buffer from the BufferPool, and once it is done, release the buffer back to the BufferPool to reuse again. This way we reduced the memory allocation calls.
BufferPool is implemented in similar lines of Sync.Pool. The only difference is Sync.Pool goes through GC, but BufferPool does not.