Building a machine learning model to solve a business problem and making it work well on the test data is only half of the battle. The job is not done until the model is really producing business value in the production environment. Making an ML model run in the production environment is very challenging and needs a lot of components and integration. In fact, ML model code is only a small fraction of the real-world ML system as described in this famous paper.
Tech/Engineering, Innovation Series
MLOps: Deploying AI/ML Models into the Production Environment

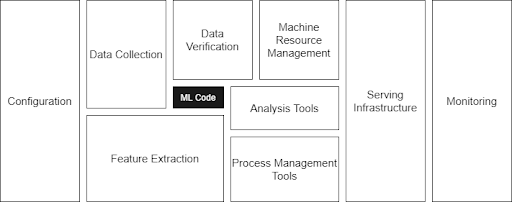
MLOps (machine learning operations) can be defined as a set of tools and practices to deploy and maintain ML products in production reliably and efficiently.
ML Project Lifecycle
At a very high level, the stages of ML project lifecycle are:
- Define — Scoping the project
- Data — Defining and organizing the data
- Modeling — Selecting and training the model
- Deployment — Deploying the trained model in production and then monitoring/maintaining it
ML is an iterative and continuous process, so we can see a lot of back and forth in these stages for various reasons. For example, one of the reasons for re-training could be data drift. Data drift is the change in the distribution of the data on which the model was trained and the current production data.
MLOps CI/CD Pipeline
Similar to DevOps, the automation of ML workflows can be managed by using CI/CD best practices. In contrast to DevOps where we only need to track the changes of the code, in MLOps we need to track the changes of the data and model as well.
Data, model, and code are the three axes of change in an ML application, and those need to be versioned properly. Versioning will also help in reproducibility. The MLOps CI/CD pipeline architecture could be designed as:
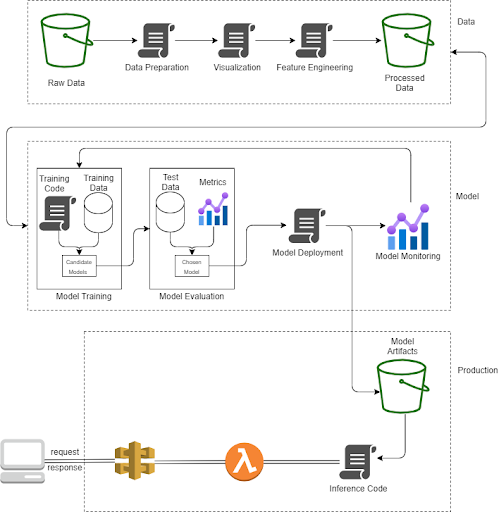
At a high level, there are three stages of an MLOps pipeline:
- Data pipeline — Transforming raw data into processed data by using data preparation, visualization, and feature engineering scripts.
- Model pipeline — Training the models and choosing a model which is performing the best on the test data to be deployed in the production. Model monitoring is not just for the standard infrastructure metrics, but also for the data and model prediction performance.
- Production environment — The deployed model is accessible as an API endpoint. The model artifact contains the model and the associated feature engineering scripts.
The stages of the pipeline are iterative and based on performance metrics; model training needs to be re-initiated from time to time. If required, the data pipeline can also be re-initiated.
MLOps Pipeline Characteristics
An MLOps pipeline must also be reproducible apart from being reliable, reusable, maintainable, and flexible. Without reproducibility, it would be impossible to determine if a new model is better than the previous model. The MLOps pipeline automatically bundles all related versions of the data, code, and model, otherwise it would be a nightmare to manage and track all these components manually.
MLOps Pipeline Testing
Automated testing helps identify the issues quickly and in their early stages. The data must also be validated for a sanity check before processing. The MLOps pipeline contains the test scripts in case any code breaks, and all tests need to be passed or else the pipeline will stop. Similarly, if all the models are not meeting minimum performance metrics criteria, none of them will be deployed and the pipeline will end there. Finally, there is integration testing for the end-to-end complete pipeline.
MLOps Platforms
There are many MLOps platforms available in the market to start with, such as Amazon sageMaker, Azure Machine Learning, Google Cloud AI, DataRobot, IBM Watson Machine Learning, and more. A new user can start quickly with open-source MLOps tools like Kubeflow, MLflow, Metaflow, etc. to learn more about MLOps.
MLOps Pipeline Performance
We should consider a cloud-first strategy for the training and deployment of ML models at scale. It will ensure the high availability of the ML model in production. We will also get the flexibility to choose the right instance type based on the model size, computation requirements, and number of requests to be served.
Skills Required for a MLOps Team
To be successful in productionizing ML models, we need the skills of both worlds: ML and software. Data scientists research and create the best possible models, while MLOps teams deploy the models into the production environment and maintain them. This is a very highly collaborative effort that includes data engineers. Data engineers manage the data pipeline, which is useful to transform raw data into processed data to be consumed directly for the training.
Key Takeaways and Next Steps
MLOps is an emerging field that helps to realize the actual business value of data science work by productionizing the models in an efficient, simple, and automated way. ML is experimental in nature which makes it even more important to follow the best practices of MLOps to standardize its processes. There is a learning curve to MLOps in either case — from a data science background or DevOps.
Looking to learn more about the technical innovations and best practices powering cloud backup and data management? Visit the Innovation Series section of Druva’s blog archive.