Druva’s backup solutions were architected from the beginning to be cloud-native and built on AWS. Druva has built many applications on top of these cloud-native backup solutions which deliver additional value to customers; among these are solutions to help ensure customer cyber resiliency and resistance to ransomware. One of Druva’s new and innovative features to predict and prevent malicious attacks on customer data is Unusual Data Activity (UDA) detection.
In a typical attack, a malicious user or software modifies data in a suspicious manner on a device. This modification is considered UDA, and Druva inSync, Druva’s SaaS-based platform for protection and management across endpoints and cloud applications, leverages UDA detection to provide reports which help identify suspicious activity, such as:
- Large number of files deleted or added
- Unwarranted modification of files
- Suspicious encryption of files
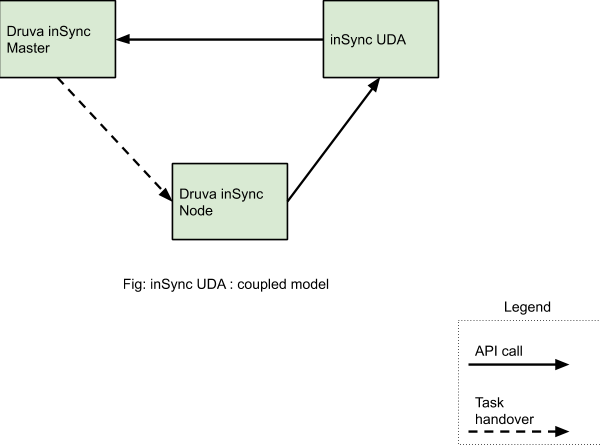
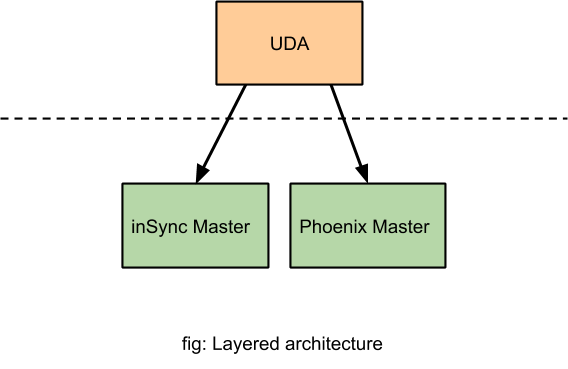
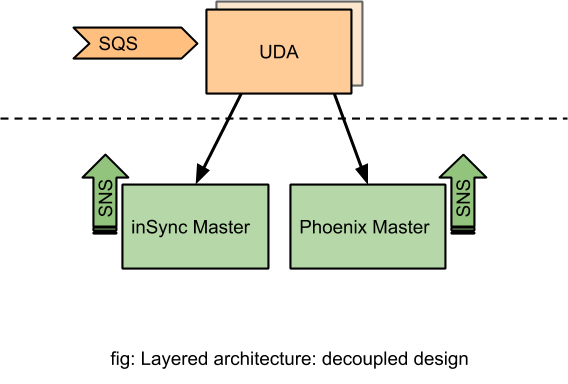
This UDA feature was primarily available to inSync customers as it had extensive dependency and coupling with the endpoint backup framework. In short, this means the following:
- The coupling was in the form of REST APIs. The workflow of backup finish, detection of anomalies and submitting the result back to inSync Master service was done in a synchronous way. There was a two-way REST API communication between the inSync Master service and UDA service.
- The endpoint backup framework is made up of multiple smaller services which facilitate the execution of backup and recovery functions, these include: syncer service, master config. server, backup manager service, API service, node service, storage service, and user portal service.