Druva’s data protection solution has visibility into the lifeblood of your business – your data. Therefore, beyond protecting the data, Druva’s innovation team is focused on helping its customers with more than just backup and recovery. For example, we enable innovative capabilities and benefits for Druva customers such as metadata search within backed up data.
But first, before we could enable capabilities such as search, we needed the underlying capability to support search across the massive amount of data we protect for our customers. At Druva we perform more than 4 million backups every single day. This means search capabilities for backup event data must be enabled across an unprecedented scale. How did we create the foundation to enable search of the big data from the backup events we handle for customers?
Big data scalability for innovation
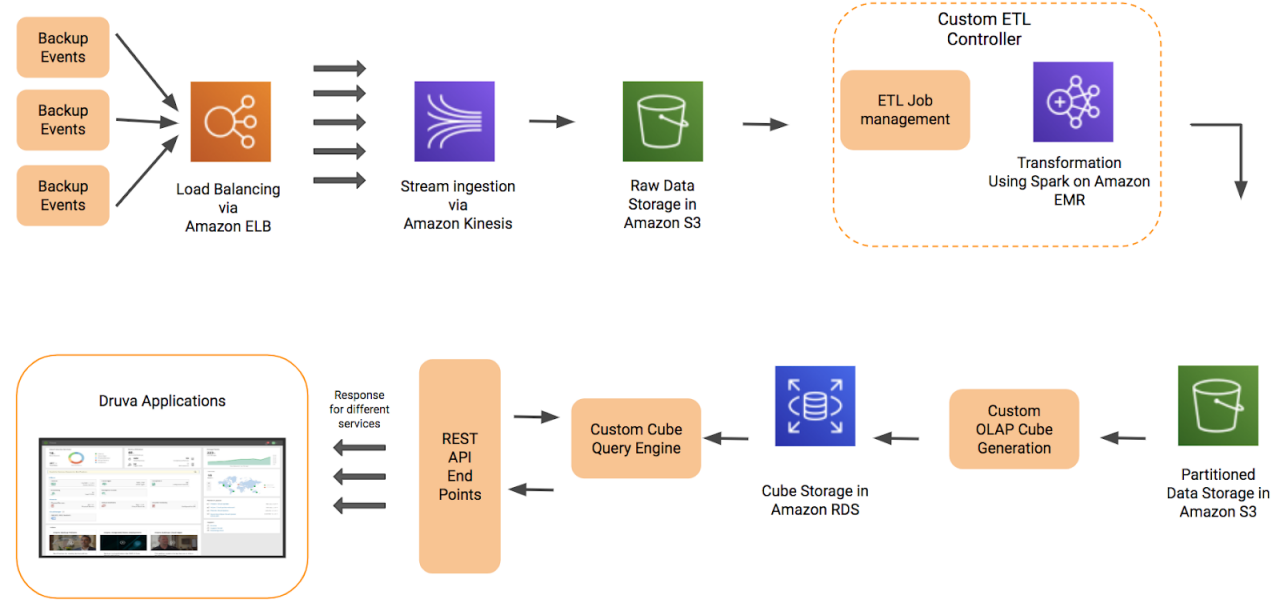
Conventional data management and querying techniques are not scalable enough to handle billions of backup events. While our competitors are confined to appliances and physical space, we live and thrive in the cloud. To transform backup event data into an asset, we built hyper-scalable, high performance big data analytics pipelines in the cloud. These pipelines ingest unstructured data about the billions of backup events and the utilization of the corresponding infrastructure and transform that for innovation into Druva products. One example is generating insights for compliance and eDiscovery.
Druva internal data analytics platform
As we designed our internal data analytics platform we had critical design criteria to consider:
- Rapidly reduce storage costs
- Serve up to 25K events/sec elastically
- Fast deployment and iteration (of data pipelines)
- Sub-second query response time for high interaction use cases
We built the platform using a suite of AWS services coupled with our custom solutions for faster and cost effective query processing. For instance, we built on-demand scaling to manage loads across the pipeline for ingestion, data partitioning, and query processing. Raw data is streamed real time and is ingested via AWS Kinesis. Running Spark on Amazon EMR with custom ETL (Extract, Transform and Load) management, the raw data is transformed, and partitioned. For fast, ad hoc queries, our query engine uses Presto, leveraging its distributed query engine capabilities on large datasets.