Organizations are confronted with more security threats and data loss risks than ever before—and even with the best technology and processes in place, it’s only a matter of time before disaster strikes. That’s why it’s absolutely essential that you have a comprehensive cloud-native backup and disaster recovery (DR) solution in place. This should not be viewed as a “nice to have” insurance policy, but instead, it should be treated as a strategic business continuity initiative.
Why Cloud-Native Backup and Disaster Recovery?
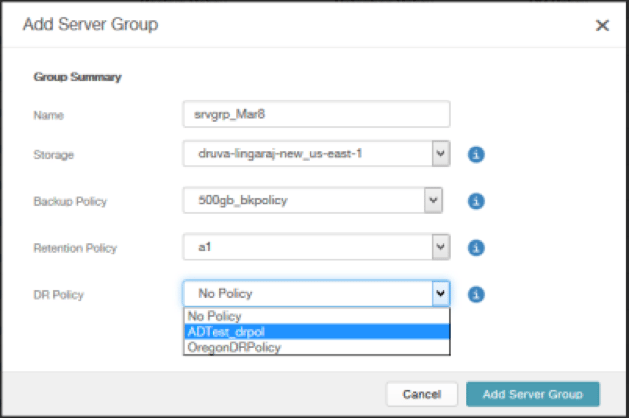
A cloud-native back up and DR solution utilizes technologies such as the global deduplication of virtual data, ensuring that only one copy of each file is maintained. This allows you to have bandwidth savings of up to 80 percent and ensures that even remote office locations, potentially with suboptimal WAN speeds, are still effectively protected.
Leveraging the efficiencies of public cloud vendors like Amazon Web Services (AWS) allows you to take advantage of tiered storage—with data sorted into hot, warm, and cold storage depending on retention and recovery needs.
The result? Long-term storage at an affordable price.
What Is DRaaS?
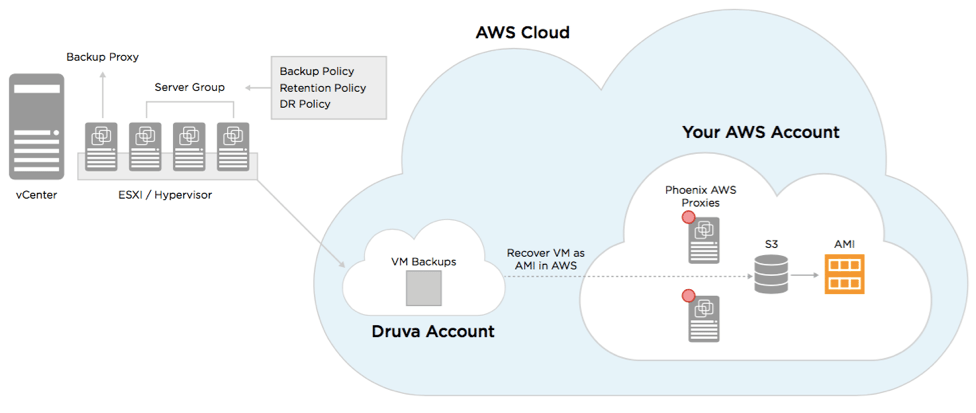
Druva provides true Disaster Recovery as a Service (DRaaS) by using the power of a cloud-native architecture and the reliability of AWS to deliver best-in-class security and availability of your virtualized data. Your IT team can confidently protect virtual machine (VM) workloads in the event of a DR scenario, while maintaining uptime, without the expense and complexity of additional data center hardware and personnel. Virtual images are replicated easily across regions for true workload mobility, whether to meet regulatory requirements or for your test/dev needs. Plus, global deduplication and auto-tiering of your storage give you significant bandwidth reduction and unparalleled TCO savings.
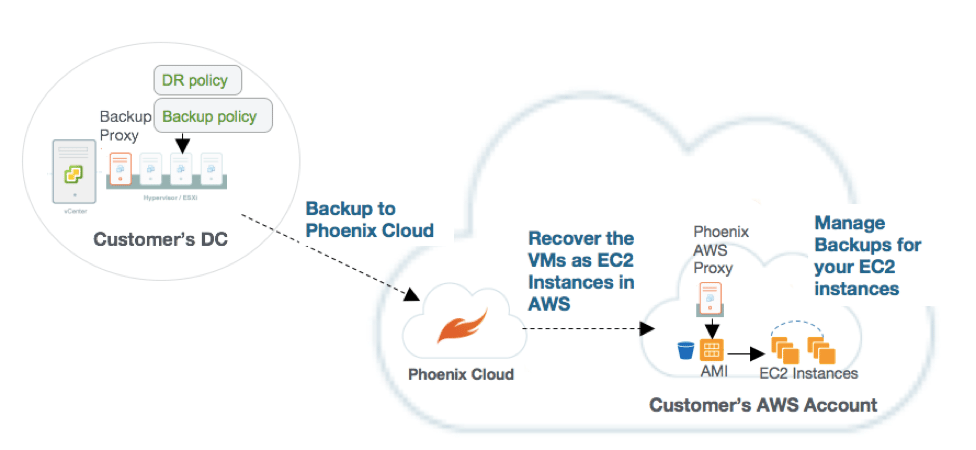
How Druva DRaaS Works
With Phoenix DRaaS, Amazon Machine Image (AMI) copies are created based on the VM backup and maintained in the AWS cloud. When a disaster strikes, you can launch an EC2 instance from these AMIs, which will spin up to production in minutes. The AMI copies are then updated with the latest VM backup based on the defined schedule.