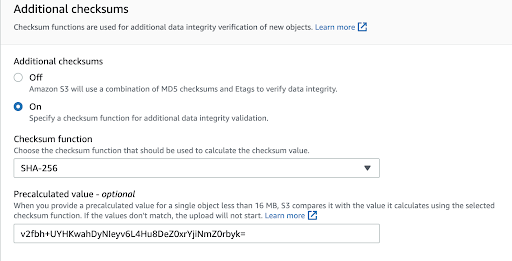
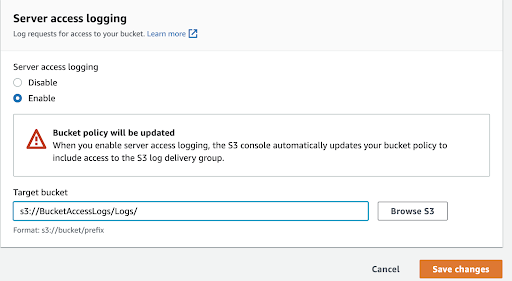
In the previous part of the five parts series, we discussed how we can achieve data confidentiality in Amazon S3. In this third of the five parts series, we will discuss how to achieve data integrity using various Amazon S3 features. We will cover integrity validation for CloudTrail log files, objects uploaded to Amazon S3, and enabling Amazon S3 server access logs.
Digest files in CloudTrail for Amazon S3 Bucket Events Logs Integrity
Validated log files are invaluable and critical in security and forensic investigations. To determine whether a log file was unaltered after CloudTrail delivered it, you can use CloudTrail log file integrity validation — a feature built using industry-standard algorithms (SHA-256 for hashing and SHA-256 with RSA for digital signing). When you enable the log file integrity validation feature, CloudTrail creates a hash for the log file that it delivers. In addition, CloudTrail creates and delivers a file that references the log files along with the hash value of each. This file is called a digest file and is created every hour. CloudTrail assigns each digest file using the private key of a public and private key pair, meaning you can use the public key to validate the authenticity of the digest file. The CloudTrail key pairs are unique to each AWS region. The CloudTrail digest files and logs are delivered to the same Amazon S3 bucket which may contain logs for multiple regions and AWS accounts (for example, if you have an organization trail). It is a good practice to store your CloudTrail logs in Amazon S3 for the maximum retention possible, based on your organization’s retention requirements. To enhance the security of the digest files stored in Amazon S3, it is recommended to enable Amazon S3 MFA Delete.
To enable log file integrity validation in CloudTrail, go to the AWS CloudTrail console and select CloudTrail. Under “General Details,” click “Edit.” Scroll down to “Additional Settings,” select “Enabled” and click “Save Changes” to complete. When enabled, the digest files will be saved in the Amazon S3 bucket.